Last week I wrote about how you can configure user selectable Essbase connections on a Dodeca view. One of the comments on the blog article was from a Dodeca customer that said, “Hey, that’s great and all, but what about a Dodeca view with multiple Essbase connections?” In other words: Can we setup a Dodeca view that pulls data from multiple user-selectable connections and have data from different connections on the same sheet? The answer is yes – although the configuration is just a tiny bit different than what I thought it would be (it was actually simpler). This blog post will walk through how to set this up.
Dynamic Essbase Connections in Dodeca: Faster Cubes and an Enhanced User Experience
The other week I showed an innovative approach to providing user-selectable Essbase connections from a Dodeca view. I’m going to continue on the subject of dynamic Essbase connections this week, but with a bit of a twist. I’m really excited to show this technique off because it’s a perfect combination of showing the flexibility that Dodeca provides, but perhaps even more importantly it speaks so strongly to our raison d’être: making Essbase better.
Current Cube vs. History Cube
Many organizations spin off a copy of their cube each year or periodically when they need to boost performance a bit. Typically the major win for performance here is that you can drop a year or more of data, often by literally deleting a member or two from the Years dimension. In an ASO cube, this can significantly cut down on the amount of data in play (thereby increasing some combination of load and query performance), and in BSO databases, the effect can be even more dramatic, particularly depending on whether years is sparse or dense. Years (FY17, FY18, etc.) is typically a sparse dimension, but is sometimes dense, which could yield even more reasons to try and keep it as small as possible.
User Selectable Cube Connections in Dodeca
A request came in the other day asking if it was possible to make a Dodeca view’s connection dynamic/selectable by the user. For example, say you are rotating through cubes every month that are essentially the same outline but just have different data. You might have the January cube, the February cube, and so on. This is a somewhat unorthodox, but certainly not unique design approach that I have seen over the years. Among other things, this approach can help keep a cube very manageable/fast when an organization’s data needs and processes might otherwise require an entirely new dimension or other dimensional shenanigans in order to facilitate the necessary reporting, planning, and forecasting activities.
To start, since connection objects in Dodeca are centrally managed it is certainly possible to just update the connection details as needed and point to the proper cube. But in this case we need a little more power. Can we let the user choose the connection for their own Dodeca view? Absolutely. I’ll show you how in this article. Continue Reading…
Improving MySQL JNDI Connection Reliability
I blogged quite some time ago about using JNDI to configure database connections in Dodeca. As I mentioned then, JNDI can bring some useful improvements to your configuration, management, security, and administration of your environment versus how you might be configuring normal JDBC connections. To be clear, this isn’t because JNDI connections are inherently better from a performance standpoint, it’s just that it might be a cleaner solution in various ways.
My original blog post looked at configuring a pretty typical MySQL connection in JNDI. As I have worked with this in the last few months, I have run into a few issues with the configuration as it related to connection timeout issues. I was occasionally getting some timeout issues like this:
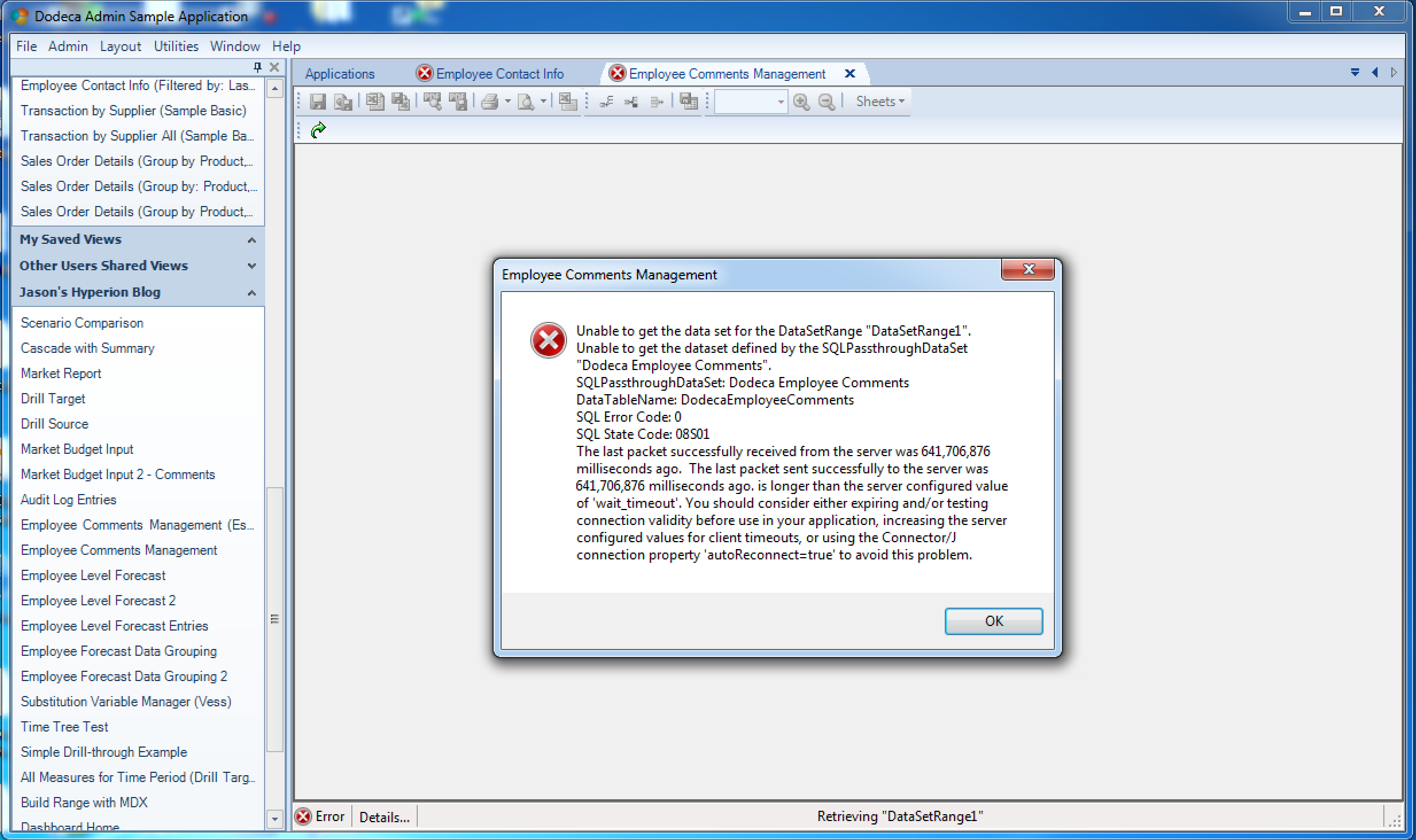
MySQL connection timeout when configured with JNDI
Helpfully enough (or perhaps unhelpfully) the error message itself reports that perhaps the autoReconnect=true setting would be of help. I’ve actually used that setting in the past and it seemed to help things out. But as it turns out, that setting is deprecated and should not be used. There are some alternative techniques that can/should be used to ensure the program gets a valid connection back.
One common technique is to specify a “validation query”. This is often something like SELECT 1 or SELECT 1 FROM DUAL depending on the particular database technology being used. You can use SELECT 1 for MySQL. What this essentially means is that before returning a connection via JNDI to the Java servlet to do things with, the connection pool manager is going to run the validation query to ensure that it is indeed a valid connection (able to connect, doesn’t error out, and so on.
Interestingly enough, MySQL in particular has added an optimization for this use case such that you can give it a sort of fake query (code: /* ping */) and it’s slightly more optimized than the overhead involved with a SELECT 1.
Together with this optimized test query, some additional attributes on the JNDI configuration (testWhileIdle, testOnBorrow, testOnReturn, and removedAbandoned, I’ve updated the overall JNDI configuration and it seems to be much more robust. Here’s the new connection JNDI code from my Tomcat context.xml:
<Resource name="jdbc/dodeca_sample" auth="Container" type="javax.sql.DataSource" username="dodeca" password="password" driverClassName="com.mysql.jdbc.Driver" url="jdbc:mysql://localhost/dodeca_sample?noDatetimeStringSync=true" maxActive="100" maxIdle="30" maxWait="10000" removeAbandoned="true" removeAbandonedTimeout="20" logAbandoned="true" validationQuery="/* ping */" testWhileIdle="true" testOnBorrow="true" testOnReturn="false" /> <ResourceLink name="jdbc/dodeca_sample" global="jdbc/dodeca_sample" type="javax.sql.DataSource"/>
Dodeca Zebra Striping with WBS Example
I wanted to punch up a Dodeca view the other day by putting a little zebra striping on some relational data. Although having built-in support for this is on my wishlist, for now a simple workbook script (WBS) gets the job done. This is also alternatively called “greenbar”… depending on what decade you were born in.
The technique itself is pretty simple. You can accomplish this in a few ways in Dodeca (as with everything), so here’s one way to go. First, when the view is opened, we have a workbook script to set a color index (that’s the first step in the following screenshot). In this case I am setting a very light grey to be color Index 2.
In the next step (the one that actually does the striping), I have defined a simple method that applies to a range named “Address” and just paint every other row depending on if it’s even or not. I’m just using the formula =MOD(@CRow(), 2) = 0, which is a normal Excel function (modulus), and a workbook script function (@CRow()) that returns the current row number being processed. If it’s even, then the cell should be painted. If not, nothing happens. So if you wanted two different colors you’d just add a new color set step and a new SetFill method that applied to odd rows.
Here’s a screenshot of the full WBS:

Dodeca WBS Zebra Striping Example
Interesting Time Period Conversion with Drillbridge/PBCS
I recently helped a customer with their Drillbridge installation/configuration for PBCS that had an interesting time period conversion issue I wanted to write about.
Drillbridge helps convert a given POV into a SQL query, webpage link, MDX query, or whatever you want (such as with a custom plugin). Out of the box, Drillbridge contains a number of commonly-used convenience functions for easily converting months to numbers (as well as other functions). You can do this in SQL too but it seems to almost always be a little “cleaner” to let Drillbridge do it for you, especially when it comes to upper-level drill-through.
Interestingly enough, a client has an interesting but not incredibly uncommon fiscal calendar where February is actually period 1, March is 2, and so on. In this calendar, January is actually period 12. But the Drillbridge calendar conversion functions usually return the common month numbers. What to do? Just adjust the expression a little to check for January specifically, otherwise convert the month and subtract one. For example:
SELECT 1 WHERE FROM DUAL WHERE
PERIOD IN ({{"name":"Period","expression":"#Period == 'Jan' ? 12 : #monthAbbreviationToDigit(#Period) - 1","drillToBottom":true,"sampleValue":"Q1","quoteMembers":false,"suppressParentheses":true,"overflow":"","overflowAt":0,"flags":""}})
There are a few variant methods to handle this, but this one is pretty straightforward and clean. This token actually also handles upper level drill (such as from member Q1, Q2, and so on), so the query predicate to use is a SQL IN clause, to accommodate multiple values.
Now when we drill on member January, we get this test query:
SELECT 1 WHERE FROM DUAL WHERE PERIOD IN (12)
And if we drill on Q1, for example, we get this:
SELECT 1 WHERE FROM DUAL WHERE PERIOD IN (1, 2, 3)
You might have been expecting to see 12, 1, 2 there but it’s actually right since Q1 contains February, March, and April – so everything is mapping as expected.
I’ve been pretty happy over the years with how the original Drillbridge expression/token concept has been able to accommodate some tricky use cases, although this one is relatively straightforward. It’s also nice to be able to write a bit of a “pure” query that doesn’t have to join against a calendar table just to get the right dates. This is just one of the things that makes Drillbridge, in my opinion, a true turnkey drill-through solution.
Small update of Hyperion Parent Inferrer to 1.0.2
Over the years I have developed a fairly robust set of Java libraries that help me work with and enhance Essbase/Hyperion functionality. One of those seemingly trivial libraries is the “Hyperion Parent Inferrer”. It’s a Java library/command-line program that can quickly parse an indented file or String and infer what the parents of members are. In the world of programming it can be nice to just have a clean hierarchy instead of fiddling around with parents/children and other things.
While the library typically processes files, I added some new functionality that I needed helps process a String into a map that can easily lookup children of parents. The updated library is on the Hyperion Parent Inferrer GitHub page. You can also find some background on the library on the README file. You might also want to check an earlier blog post on the library, if that’s your thing.
Webinar Tomorrow: One Stop Data Shop with Dodeca
I just wanted to plug a webinar that I am conducting tomorrow on Dodeca. I’m excited to do this webinar for a few reasons. Usually on our monthly webinar series we look at a specific feature and do a technical walkthrough. The focus of this webinar is a little different, though. This is more of a case study looking at how a business has a lot of existing processes and reports built around Essbase and the Excel add-in, but needs something more sophisticated to handle their needs, including:
- Using Dodeca to build views based on existing Excel sheets that need to fetch data for multiple tabs and multiple data sources in one fell swoop
- Facilitate user input directly to Essbase with commentary
- Combine Essbase and relational data in a single view (and save user’s a trip to a tertiary system!)
- Drill-through in Dodeca: not just from Essbase to relational but Essbase to Essbase or relational to relational
- Batch reporting
Having consulted in the Hyperion/Essbase world for many years I can easily say that there were countless organizations with sophisticated and complicated (but tried and true) Excel/Essbase-based processes that would greatly benefit from a tool that helped automate, manage, and control things. So that’s exactly what I hope to convey tomorrow during the webinar. If you’d like to attend, please register and I’ll look forward to showing you Dodeca and taking your questions!
New Substitution Variable Methods/CLI in PBJ
Just a few additions to the PBJ (PBCS REST API Java Library) regarding substitution variables. All of the new functionality is added to the PbcsApplication interface, for now. Since variables can exist in a specific plan type, it may make sense in the future to add a new interface/implementation that models a specific plan type. Anyway, here are the four new methods for now:
/** * Gets all substitution variables in the application * * @return a list of the substitution variables, an empty list if there are * none */ public Set<SubstitutionVariable> getSubstitutionVariables(); /** * Fetch a substitution variable with a particular name from this * application * * @param name the name of the variable to fetch * @return the variable object, if it exists * @throws PbcsNoSuchVariableException if the variable does not exist */ public SubstitutionVariable getSubstitutionVariable(String name); /** * Update a set of substitution variables. This does not replace all of the * variables in the application, it just updates the ones that have been * specified in the collection (contrary to what the REST API docs seem to * imply) * * @param variables the variables to update */ public void updateSubstitutionVariables(Collection<SubstitutionVariable> variables); /** * Convenience method to update a single substitution variable value. * * @param name the name of the variable * @param value the value of the variable */ public void updateSubstitutionVariable(String name, String value);
A few things to note:
- The
getSubstitutionVariablesmethod returns aSet<SubstitutionVariable>, as opposed to a List. Since a variable should be unique with respect to its combination of plan type, name, and value, a Set makes a little more sense here because the ordering implied by a List is irrelevant - All methods work with/return a
SubstitutionVariableobject. This is a new POJO class with three fields:planType,name, andvalue. - You can fetch just a single substitution variable by name as a convenience method. Although there is a technically a specific REST API endpoint for doing so, right now it just calls the other method and filters it.
- You can update a set of variables
- As a convenience, you can update a single variable/value for all plan types using the
updateSubstitutionVariable(String name, String value)method.
The PBJ CLI (an “über” JAR that is runnable an implements a basic CLI to PBCS) has also gotten a couple of updates to reflect the new capabilities in the library. For example, you can quickly list all variables in an app:
java -jar pbj-pbcs-client-1.0.4-jar --conn-properties pbcs-client.properties list-variables --application=Vision
And get a list back:
ALL,NextPd,FY15 ALL,CurrPd,FY14
And as an added bonus, you can even provide your own format string if you want. This might help for people doing automation and need to get the data into a particular format with having to do some weird batch/shell string tweaks:
java -jar pbj-pbcs-client-1.0.4-jar --conn-properties pbcs-client.properties list-variables --application=Vision --format=%s|%s|%s%n
ALL|NextPd|FY15 ALL|CurrPd|FY14
All For Now
These latest updates are in the 1.0.4 branch of the PBJ GitHub repository. You can clone it and build your own copy of the library and runnable CLI JAR (if you’re so inclined) by checking that out. Eventually this branch will be merged into the master, pending more testing.
Understanding the Outline Extractor Relational Extraction Tables
I was going to do a nice in-depth post to follow up on my discussion of the relational cache outline extraction method/improvements on the Next Generation Outline Extractor, but someone already beat me to the punch. It turns out that the tool’s primary author, Tim Tow, blogged about the technique and the tables for ODTUG a couple of years back.
I’ll just add on one thing that I wanted to highlight, though: the general technique behind most relational extractions from an Essbase outline is to generate a single table, with such common columns as PARENT, CHILD, ALIAS, UDA, STORAGE, CONSOLIDATION, and so on. If you think about this, it tends to imply a number of limitations that might make this technique unfeasible for you:
- The table can only hold one extraction at a time
- You can only get the member name and a certain alias table alias at a time
- The columns in the table are variable based on the attribute dimensions that may be associated with the dimension
- More than one UDA: ¯\_(ツ)_/¯