Drillbridge 1.4.0 is coming out later this month and it contains some really cool features. Today I am going to go over one of them. This feature is called “Custom Mappings” and while it’s ostensibly simple, it is a huge win for drill-through and cube design.
Consider the scenario where you are drilling from a member in the Time dimension. Drilling from January (Jan), February (Feb), and so on are straightforward (especially with Drillbridge’s convenience methods for mapping these to 01, 02 and such). Even drilling from upper-level members is a snap – Drillbridge gets handed the member Qtr1, for example, then opens the outline to get the three children, then applies the mappings to those and plugging it into the query (so the relevant query fragment might be WHERE Period IN ('01', '02', '03') or something.
Everything is great, right? Well, what about those YTD members you often see in ASO cubes as an alternate hierarchy? Something like this:
- YTD (~)
- YTD_Jan (~) Formula: [Jan]
- YTD_Feb (~) Formula: [Jan] + [Feb]
- YTD_Mar (~) Formula: [Jan] + [Feb] + [Mar]
- etc.
The problem with these members is that they are dynamic calcs with no children. So if you try to drill on this, then Drillbridge would literally be querying the database for a period member named “YTD_Feb”, for example.
I have sort of worked around this before in Studio by instead putting shared members under these. Under YTD_Jan you have a shared member Jan, under YTD_Feb you have shared members Jan and Feb, and so on. This works, although it’s a bit cumbersome and feels a little clunky.
Custom Mappings to the Rescue!
Custom Mappings is a new Drillbridge feature that allows you to specify a list of member names to use when drilling on certain member names. If a Custom Mapping is added to a report, Drillbridge will consult that first for child member names. If a mapping isn’t found then Drillbridge will just use the normal provider of mappings (e.g. it’ll open the cube outline and use that).
All that’s needed to create custom mappings is to put them in a file. Here’s an example:
YTD_Jan,Jan
YTD_Feb,Jan
YTD_Feb,Feb
YTD_Mar,Jan
YTD_Mar,Feb
YTD_Mar,Mar
YTD_Apr,Jan
YTD_Apr,Feb
YTD_Apr,Mar
YTD_Apr,Apr
YTD_May,Jan
YTD_May,Feb
YTD_May,Mar
YTD_May,Apr
YTD_May,May
YTD_Jun,Jan
YTD_Jun,Feb
YTD_Jun,Mar
YTD_Jun,Apr
YTD_Jun,May
YTD_Jun,Jun
YTD_Jul,Jan
YTD_Jul,Feb
YTD_Jul,Mar
YTD_Jul,Apr
YTD_Jul,May
YTD_Jul,Jun
YTD_Jul,Jul
YTD_Aug,Jan
YTD_Aug,Feb
YTD_Aug,Mar
YTD_Aug,Apr
YTD_Aug,May
YTD_Aug,Jun
YTD_Aug,Jul
YTD_Aug,Aug
YTD_Sep,Jan
YTD_Sep,Feb
YTD_Sep,Mar
YTD_Sep,Apr
YTD_Sep,May
YTD_Sep,Jun
YTD_Sep,Jul
YTD_Sep,Aug
YTD_Sep,Sep
YTD_Oct,Jan
YTD_Oct,Feb
YTD_Oct,Mar
YTD_Oct,Apr
YTD_Oct,May
YTD_Oct,Jun
YTD_Oct,Jul
YTD_Oct,Aug
YTD_Oct,Sep
YTD_Oct,Oct
YTD_Nov,Jan
YTD_Nov,Feb
YTD_Nov,Mar
YTD_Nov,Apr
YTD_Nov,May
YTD_Nov,Jun
YTD_Nov,Jul
YTD_Nov,Aug
YTD_Nov,Sep
YTD_Nov,Oct
YTD_Nov,Nov
YTD_Dec,Jan
YTD_Dec,Feb
YTD_Dec,Mar
YTD_Dec,Apr
YTD_Dec,May
YTD_Dec,Jun
YTD_Dec,Jul
YTD_Dec,Aug
YTD_Dec,Sep
YTD_Dec,Oct
YTD_Dec,Nov
YTD_Dec,Dec
With this Custom Mapping in place on a report, drill-to-bottom can be provided on a cube’s Time dimension YTD members. You get all of this functionality without having to tweak the outline, add a bunch of shared members, or anything. And what’s even better – you’ll even save a whole trip to the outline. If there is some member that is problematic to resolve, for some reason, or you just wanted to override the member resolution process, you could also stick it in the custom mapping.
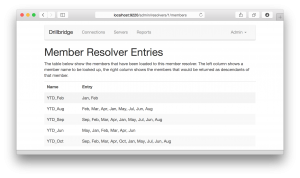
Just for completeness, let’s take a look at the admin screens for editing and updating Custom Mappings. Here’s an overview of all of the different Custom Mappings that have been created:
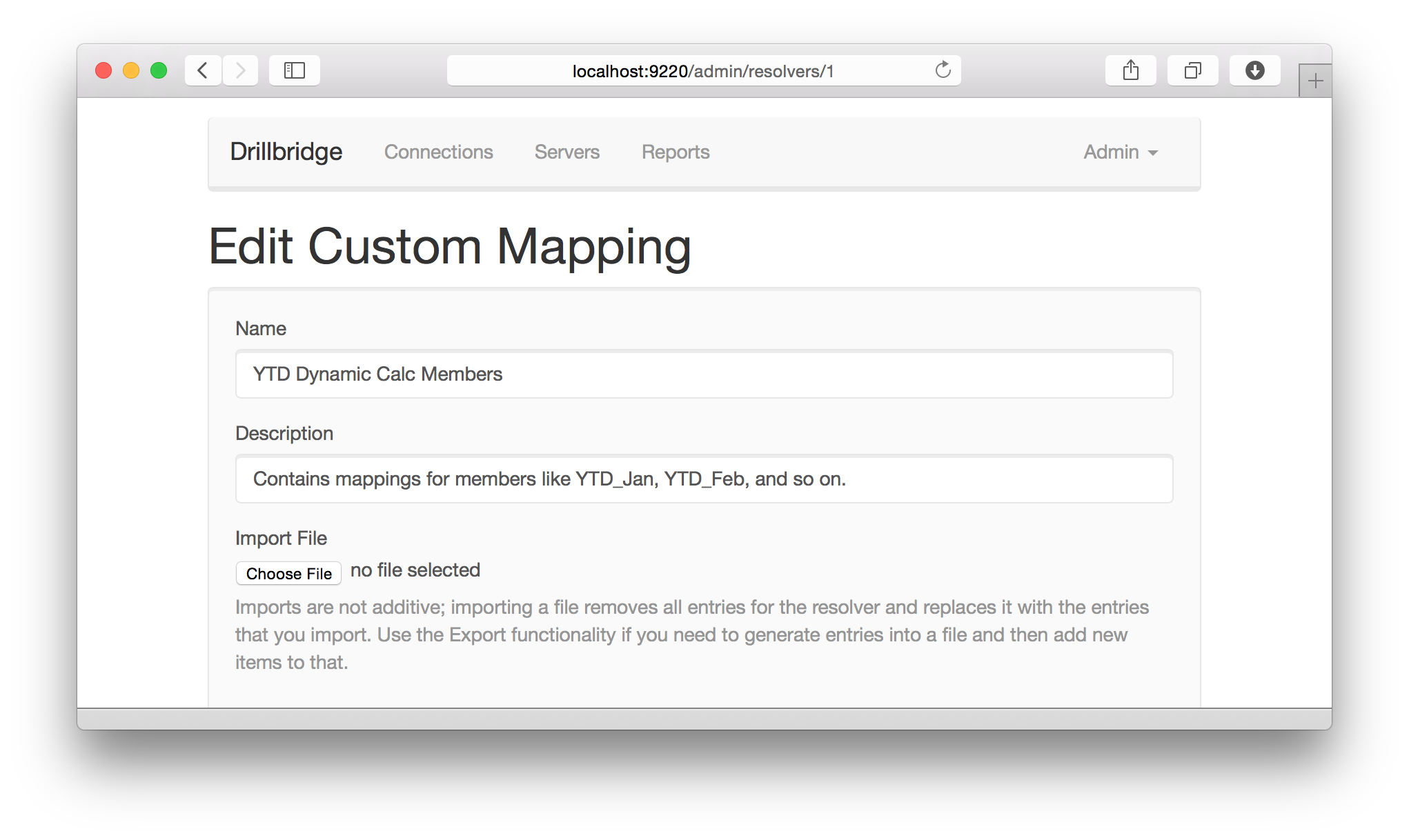
Here’s a look at editing a Custom Mapping:
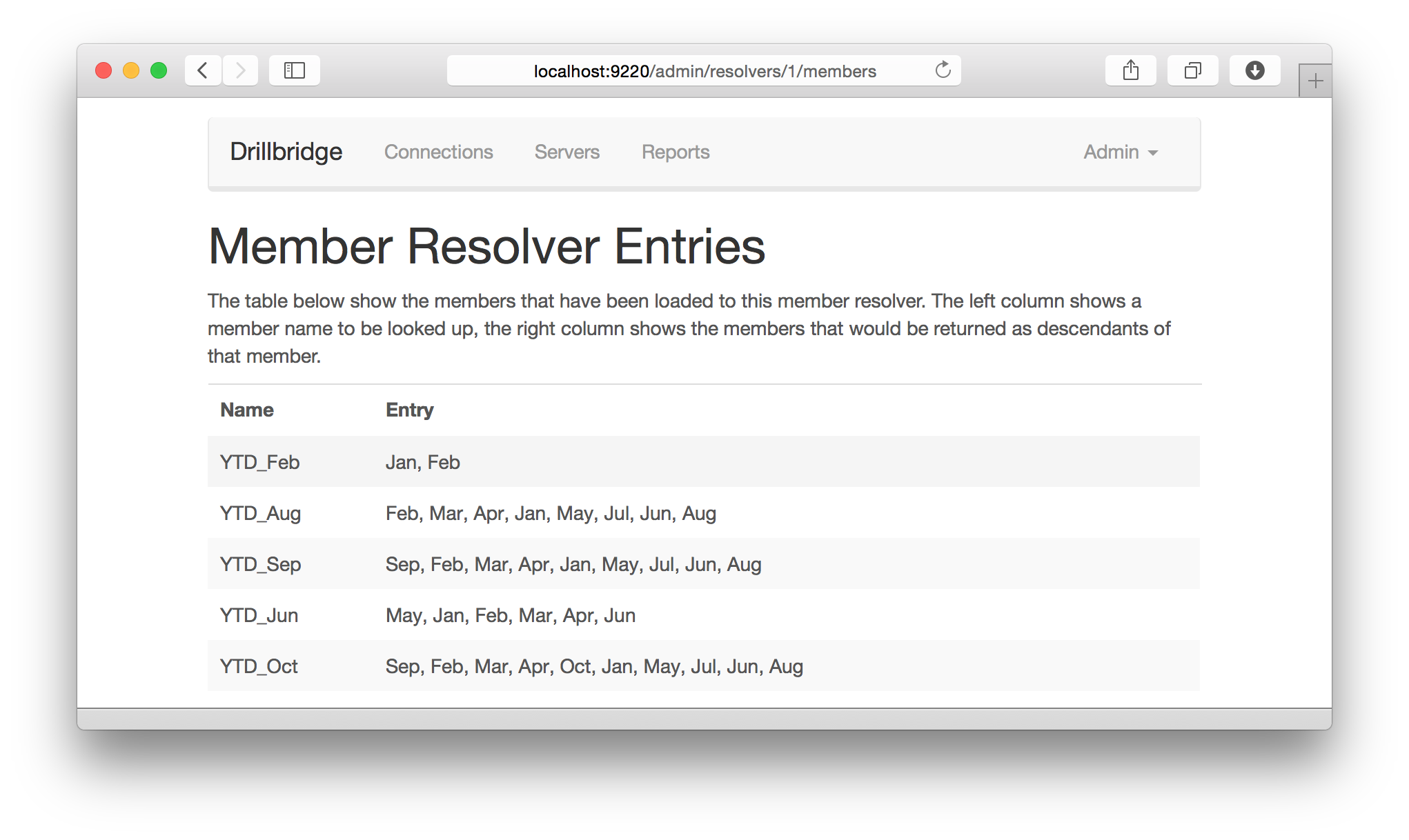
 And here’s previewing the list of individual mappings available for a given mapping (that have been uploaded by importing a text file):
And here’s previewing the list of individual mappings available for a given mapping (that have been uploaded by importing a text file):
 There you have it. As I mentioned, this feature will be available in upcoming release version 1.4.0, which should be out later this month. This feature is really, really cool, and there are a few more things this release adds that I will be talking about over the next week up to the release.
There you have it. As I mentioned, this feature will be available in upcoming release version 1.4.0, which should be out later this month. This feature is really, really cool, and there are a few more things this release adds that I will be talking about over the next week up to the release.