This isn’t one you will run into too often, if ever, but seems to be a small issue. I was working on a load rule the other day (yay load rules!) and everything validated just fine. There’s nothing better than the smell of an “everything validated correctly!” dialog in the morning. I am on a project refactoring a cube and one of the small changes made was that the dimension name has changed for one of the dimensions from Accounts to Account. One of the core load rules for this cube uses the “sign flip on UDA” feature. Of course, for this feature to work (which I have used many times before and love [but not as much as I love EIS…]) it needs to specify the dimension and the UDA of the members in that dimension to flip the sign for. Well, sign flipping wasn’t working and even though the load rule validates just fine, the problem was that non-existant dimension in the sign flip configuration. So, although there could be a reason to not want to validate this, it seems somewhat reasonable (if nothing else, for the sake of completeness) that the load rule verification should include verifying that if the dimension name for sign flipping does exist. It would have saved me a little bit of time.
Category Archives: maxl
Survey Results: What is the one true MaxL script file extension to rule them all?
I was feeling a little bit whimsical last week and wanted to get a little use out of my SurveyMonkey account, so I decided to do a quick poll: what is the proper file extension for MaxL scripts?
This issue initially arose for me when I was heckling Cameron Lackpour at one of his presentations a few years ago. My memory must be a little faulty because at the time I could have swore that he liked .mxl, whereas I am more of an .msh guy. So I wanted to settle this once and for all.
Oracle, for its part, doesn’t provide a ton of consistency on this issue, as scripts created from EAS seem to suggest a .mxl extension, whereas the script interpreter and commands seem to suggest that .msh is a little more on the recommended side. I have seen both in environments. Literally both, as in, some scripts are .mxl and some are .msh, and sometimes this naming inconsistency even exists in the same set of automation. Shudder.
Without further ado, here are the results.
- Total responses: 21
- .msh: 9 (42.9%)
- .mxl: 10 (47.6%)
- .maxl 2 (9.5%)
- Other: 1 (this wound up being entered in as .mxls)
So, there you have it. I would like to note, by the way, that if you chose other then I implied with your answer that you were a ‘monster’. I’m only half-joking. Way to think outside the box. Anyway, I haven’t personally seen .maxl scripts in production but someone on the Network54 forum commented that, hey, down with 8.3 file naming and in with the whole name as extension. I have to admit, I never really thought about this in the context of MaxL scripts, but oddly I do find it a little disgusting when HTML files have a .htm extension rather than a full .html extension.
Suffice it to say, I am more than a little disappointed with these results and than the .msh file extension lost in a neck and neck battle. I’m going to pretend that this survey never happened and that .msh is the one true script extension to rule them all.
Thank you all for submitting answers to this somewhat lighthearted survey. If you have ideas for further issues to explore and survey the community about, please send them to me and I’ll get another survey going!
Release of Jessub 1.0.0
I am happy to announce the release and open-sourcing of a nifty little chainsaw of a utility. Jessub, short for Java Essbase Substitutions, is a small text-replacing utility designed specifically to update the code in a MaxL script template by replacing specialized tokens with values you specify. You can specify the values as being almost any aspect of a date, and you can specify the date as being the current date plus or minus a number of days, months, or years.
In terms of automation, you would write a batch file that calls Jessub (a single Java jar file), giving it the name of a specially formatted MaxL file, and the name of an output file. You then call the output file with the normal MaxL interpreter. This approach can be useful when you just want to drop in a quick solution without having to code custom Java against the Essbase API. The automation is also resilient to upgrades since it’s just generating plain MaxL script.
I have frequently needed to update variables based on the current day, or a set of variables based on the current day, for use with calc scripts or report scripts. For example, I might have a process that needs to set a variable on Sunday (Day 1 of the week) to a certain value, then each day of the week, set another variable to the current day of the week at the time. Then I might run a calc script that copies data from the Forecast scenario to the current day.
Jessub provides the entire spectrum of options available to the String.format() method in Java. Essentially, you can pull out almost any aspect of the date. Combined with small format codes to roll the days/months/years forward/backward, you can generate almost any date or relative date that you need. No more getting up on the weekends to update substitution variables!
Jessub is the evolution of many similar one-off tools I have created in the past. It is generic, robust, and easy to use. I always say that a good administrator is a lazy administrator, so I hope anyone interested out there can put this to good use. The entire code base is licensed under the liberal Apache License 2.0, so you are essentially free to take the code (should be so inclined) and do absolutely anything you want to it. Although my hope is that if you find it useful, you will let me know and suggest improvements.
Jessub can be found at its project site, where you can find documentation, examples, browse the code, and a runnable JAR download file (with documentation as well). Please enjoy this free (as in speech and as in beer) utility.
A quick and dirty recipe for automating the yearly cube archive process
Due to various business requirements, I often find that one of the strategies I use for preserving point-in-time reporting functionality is to simply spin off a copy of cube. In many organizations, the Measures dimension in a financial cube (modeled on the chart of accounts) can be quite large — and a moving target. By spinning off a copy of the cube, you can provide the ability to query the cube later and recreate a report that was created earlier.
So, normally firing up EAS, right clicking on the application, and hitting copy isn’t too big of a deal. But, what if you actually have to do this to a couple dozen large cubes? Additionally, since these reside on the same server, we need to come up with different names for them. Again, do-able in EAS, but good admins are lazy, and I’m a good admin. So let’s cook up some quick and dirty automation to do this.
I’ll create a new folder somewhere to keep these files. First I will create a text file that has the current name of the application, a comma, and what the copy of the application should be named.
Here is my file, called mapping.txt:
; , x CUBE03 ,YPCUBE03 CUBE04 ,YPCUBE04 CUBE05 ,YPCUBE05 CUBE06 ,YPCUBE06 CUBE07 ,YPCUBE07 CUBE08 ,YPCUBE08 CUBE09 ,YPCUBE09 CUBE10 ,YPCUBE10 CUBE11 ,YPCUBE11 CUBE12 ,YPCUBE12
The semi-colon at the top is actually a comment, and I put it in along with the comma and the x so that in a fixed-width editor like Notepad, I can easily see that I am indeed staying within the 8-character limit for application names (remember that this is a bunch of cubes with all different names so this just helps me avoid shooting myself in the foot).
Next, we need the MaxL file. Here is the file copy.msh:
create or replace application $2 as $1;
What?! But there’s hardly anything in it! We’re going to tell the MaxL interpreter to login with parameters on the command line.
Okay, and lastly, we have the batch file (this is Windows we’re running the automation from).
:
: Parameters:
:
: server, username, password, mapping file
:
FOR /f "eol=; tokens=1,2 delims=, " %%i in (%4) do (
ECHO Original app: --%%i-- target app: --%%j--
essmsh -s %1 -l %2 %3 copy.msh %%i %%j
)
Okay, so what’s going on here? It’s a batch file that takes four parameters. We’re going to pass in the analytic server to login to, the user on that server to use (your batch automation ID or equivalent), the password for that user, and the mapping file (which happens to be the text file in the same directory, mapping.txt).
So from a command line, in the same folder as all these files, we can run this command as such:
copydb.bat analyticserver.foo.bar admin password mapping.txt
And of course replace the parameters with the actual values (although I’m sure some of you out there have admin and admin’s password is… password… tisk, tisk).
And there you have it! We can easily adapt this to copy things out next year, we didn’t leave our master ID and password buried in some file that we’ll forget about, we don’t have any hard-coded paths (we need essmsh in the PATH but that should already be the case), and more importantly, instead clicking and typing and waiting and clicking and typing and waiting in EAS (some of these app copies take awhile), we’ll let the server knock it out of the park. Be sure to watch the output from this to make sure everything is running to plan, since we aren’t logging the output here or doing any sort of parameter sanity checking or error handling.
A comprehensive Essbase automation optimization story, or: Shaving off every last second
I’ve been wanting to write this post for awhile. Like, for months. Some time ago I took an in-depth look at profiling the performance (duration-wise) of an automated system I have. The system works great, it’s worked great, I don’t need to touch it, it just does its thing. This is the funny thing about systems that live in organizations: some of the rather inglorious ones are doing a lot of work, and do it reliably. Why reinvent the wheel and risk screwing things up?
{kind=link}
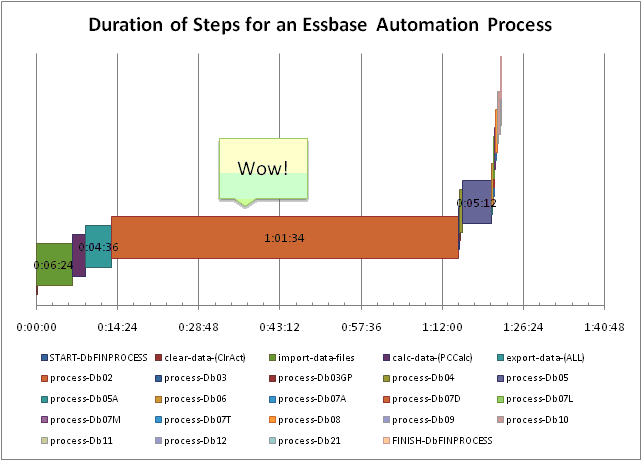
Well, one reason is that you need to squeeze some more performance out of that system. The results of my profiling efforts showed that the process was taking about an hour and a half to run. So, considering that the processing of the data is an hour behind the source system (the source system drops off text files periodically for Essbase), and it takes an hour and a half to run, the data in the cubes is some two and a half hours behind the real world numbers in the original system.
So, first, a little background on what kind of processing we have here. The gist of how this particular system works is that a mainframe manages all of the data, and certain events trigger updated files to get delivered to the Essbase server. These files are delivered at predictable intervals, and automation jobs are scheduled accordingly (about an hour after the text files are scheduled to be delivered, just to be on the safe side). The data that comes in is typical financial data — a location, a time period, a year, an account, and an amount.
Pretty simple, right? Well, there are about twenty cubes that are financial in nature that are modeled off of this data. The interesting thing is that these cubes represent certain areas or financial pages on the company’s chart of accounts. Many of the pages are structurally similar, and thus grouped together. But the pages can be wildly different from each other. For this reason, it was decided to put them in numerous cubes and avoid senseless inter-dimensional irrelevance. This keeps the contents of the cubes focused and performance a little better, at the expense of having to manage more cubes (users and admins alike). But, this is just one of those art versus science trade-offs in life.
Since these cubes add a “Departments” dimension that is not present in the source data, it is necessary to massage the data a bit and come up with a department before we can load the raw financial data to a sub-cube. Furthermore, not all the cubes take the same accounts so we need some way to sort that out as well. Therefore, one of the cubes in this process is a “staging” database where all of the data is loaded in, then report scripts are run against certain cross sections of the data, which kick out smaller data files (with the department added in) that are then loaded to the other subsequent cubes. The staging database is not for use by users — they can’t even see it. The staging database, in this case, also tweaks the data in one other way — it loads locations in at a low level and then aggregates them into higher level locations. In order to accomplish this, the staging database has every single account in it, and lots of shared members (accounts can be on multiple pages/databases).
That being said, the database is s highly sparse. For all of these reasons, generating reports out of the staging database can take quite a bit of time, and this is indicated as the very wide brown bar on the performance chart linked above. In fact, the vast majority of the total processing time is just generating reports out of this extremely sparse database. This makes sense because if you think about what Essbase has to do to generate the reports, it’s running through a huge section of database trying to get what it wants, and frankly, who knows if the reports are even setup in a way that’s conducive to the structure of the database.
Of course, I could go through and play with settings and how things are configured and shave a few seconds or minutes off here and there, but that really doesn’t change the fact that I’m still spending a ton of my time on a task, that quite simply, isn’t very conducive to Essbase. In fact, this is the kind of thing that a relational database is awesome at. I decided, first things first, let’s see if we can massage the data in SQL Server, and load up the databases from that (and get equivalent results).
The SQL Server staging database is relatively simple. There is now a table that will have the data loaded to it (this is the data that was loaded to the staging cube with a load rule). The other tables include a list of financial pages (these are the departments on the sub-cubes, so to speak), a table for the list of databases (you’ll see why in a minute), a table for linking the departments/pages to a particular database, a table linking accounts to departments (pages), a page-roll table to manage the hierarchy of how pages aggregate to “bigger” pages, and a location/recap table that links the different small locations to their bigger parent locations (this is the equivalent of the location summing from the original staging database).
With all these tables in place, it’s time to add a few special views that will make life easier for us (and our load rules):
SELECT
D.database_name
, P.physical_page
, A.account
, K.div
, K.yr
, K.pd
, K.amt
FROM
account_dept AS A INNER JOIN
jac_sum_vw AS K ON A.account = K.account INNER JOIN
page P ON A.G_id = P.G_id INNER JOIN
page_database AS G ON A.G_id = G.G_id INNER JOIN
dbase AS D ON G.database_id = db.database_id
Obviously I didn’t provide the schema for the underlying tables, but this still should give you a decent idea of what’s going on. There’s another view that sits on top of this one that takes care of the summing of locations for us, but it’s structurally similar to this one, so no surprises there. What I end up with here is a view that has columns for the database name, the department, the account, location, year, period, and the amount. So not only is this perfect for a fact table down the road when I convert this to EIS, I can also use the exact same view for all of my databases, and a very similar load rule in each database that simply references a different database.
This all took a day or two to setup, but after I started getting data how I wanted, I got pretty stoked that I was well on my way to boosting performance of this system. One of the nice things about the way it’s setup in the relational database is also that it’s very flexible — extra databases, departments, locations, and anything else can be added to one central place without too much trouble.
Interestingly enough, this entire system is one that’s been in production for years but the “test” copy of things was sort of forgotten about and completely out of sync with production. Since I was getting closer to the point where I was ready to load some cubes, I needed to sync test to prod (oddly enough) so I could do all testing without hosing things up. Basically I just copied the apps from the production server to the test server with EAS, copied the existing automation folder, changed some server names and passwords (which were all hard-coded, brilliant…), and was pretty much good to go. On a side note, I took the opportunity to rewrite the automation in modular, test-ready form (basically this involved cleaning up the old hard-coded paths and making it so I could sync test to prod much easier).
My next step was to design a load rule to load data up, to make sure that the structure of the tables and views was sufficient for loading data. I did a normal SQL load rule that pulled data from the view I setup. The load rule included some text replacements to adapt my version of departments to the actual alias name in the database, but otherwise didn’t need anything major to get working. I loaded one period of data, calculated, saw that I was off a bit, researched some things, tweaked the load rule, recalculated, and so on, until finally the numbers were tying out with what I was seeing. Not bad, not bad at all.
After this basic load rule was working correctly, I started gutting the automation system to clean things up a bit more and use the new load rule (with the old calcs). After I felt good about the basic layout of things and got to the point where I was ready to copy this out to the other 18 or however many cubes. Then I put some hooks in the automation to create a log file for me, so I can track performance.
For performance profiling, I used a technique that I’ve been using for awhile and have been quite happy with. I have a small batch file in the automation folder called essprof.bat that has this in it:
@For /f "tokens=2-4 delims=/ " %%a in ('date /t') do @set FDATE=%%c-%%a-%%b
@echo %2,%FDATE% %TIME% >> %1
Basically when you call this file from another batch file, you tell it what file you want to append the data to, what the step should be named, and it takes care of the rest. Here is how I might call it from the main automation script:
CALL essprof.bat %PROFFILE% START-PROCESS
The PROFFILE variable comes from a central configuration file and points to a location in the logging folder for this particular automation set. For this particular line, I would get output like the following:
START-PROCESS,2009-07-31 8:57:09.18
The For loop in the batch file parses the DOS/shell date command a little bit, and together with the TIME variable, I get a nice timestamp — one that, incidentally, can be read by Excel very easily.
So what’s this all for? As I did in the original performance chart, I want to profile every single step of the automation so I can see where I’m spending my time. Once I filled out the rest of the load rules and ran the process a few times to work out the kinks, I now had a good tool for analyzing my performance. Here is what one of the initial runs looked like:
start-db02-process 10:54 AM finish-db02-process 10:54 AM start-db03-process 10:54 AM finish-db03-process 10:57 AM start-db03GP-process 10:57 AM finish-db03GP-process 10:58 AM start-db04-process 10:58 AM finish-db04-process 11:13 AM start-db05-process 11:13 AM finish-db05-process 11:13 AM start-db06-process 11:13 AM finish-db06-process 11:13 AM start-db07A-process 11:13 AM finish-db07A-process 11:13 AM start-db07D-process 11:13 AM finish-db07D-process 11:14 AM start-db07L-process 11:14 AM finish-db07L-process 11:14 AM start-db07M-process 11:14 AM finish-db07M-process 11:14 AM start-db07T-process 11:14 AM finish-db07T-process 11:14 AM start-db08-process 11:14 AM finish-db08-process 11:14 AM start-db09-process 11:14 AM finish-db09-process 11:14 AM start-db10-process 11:14 AM finish-db10-process 11:14 AM start-db11-process 11:14 AM finish-db11-process 11:14 AM start-db12-process 11:14 AM
And how do we look? We’re chunking through most of the databases in about 20 minutes. Not bad! This is a HUGE improvement over the hour and a half processing time that we had earlier. But, you know what, I want this to run just a little bit faster. I told myself that if I was going to go to the trouble of redoing the entire, perfectly working automation system in a totally new format, then I wanted to get this thing down to FIVE minutes.
Where to start?
Well, first of all, I don’t really like these dense and sparse settings. Scenario and time are dense and everything else is sparse. For historical reasons, the Scenario dimension is kind of weird in that it contains the different years, plus a couple budget members (always for the current year), so it’s kind of like a hybrid time/scenario dimension. But, since we’ll generally be loading in data all for the same year and period at once (keep in mind, this is a period-based process we’re improving), I see no need to have Scenario be dense. Having only one dense dimension (time) isn’t quite the direction I want to go in, so I actually decided to make location a dense dimension. Making departments dense would significantly increase my inter-dimensional irrelevance so Location seems like a sensible choice — especially given the size of this dimension, which is some 20 members or so. After testing out the new dense/sparse settings on a couple of databases and re-running the automation, I was happy to see that not only did the DB stats look good, but the new setting was helping improve performance as well. So I went ahead and made the same change to all of the other databases, then re-ran the automation to see what kind of performance I was getting.
End to end process time was now down to 12 minutes — looking better! But I know there’s some more performance out there. I went back to the load rule and reworked it so that it was “aligned” to the dense/sparse settings. That is, I set it so the order of the columns is all the sparse dimensions first, then the dense dimensions. The reason for this is that I want Essbase to load all the data to a single data block that it can, and try to minimize the number of times that the data block is loaded to memory.
Before going too much further I added some more logging to the automation so I could see exactly when the database process started, when it ran a clearing calc script, loaded data, and calculated again.
Now I was down to about 8 minutes… getting better. As it turns out, I am using the default calculation for these databases, which is a CALC ALL, so that is a pretty ripe area for improvement. Since I know I’m loading data all to one time period and year, and I don’t have any “fancy” calcs in the database, I can rewrite this to fix on the current year and period, aggregate the measures and departments dimensions, and calc on the location dimension. By fancy, I’m referring to instances were a simple aggregation as per the outline isn’t sufficient — however, in this case, just aggregating works fine. I rewrote the FIX, tested it, and rolled it out to all the cubes. Total end to end load time was now at about four minutes.
But, this four minute figure was cheating a little since it didn’t include the load time to SQL, so I added in some of the pre-Essbase steps such as copying files, clearing out the SQL table, and loading in the data. Fortunately, all of these steps only added about 15 seconds or so.
I decided to see if using a more aggressive threads setting to load data would yield a performance gain — and it did. I tweaked essbase.cfg to explicitly use more threads for data loading (I started with four threads), and this got total process time down to just under three minutes (2:56).
As an aside, doing in three minutes what used to take 90 would be a perfectly reasonable place to stop, especially considering that my original goal was to get to five minutes.
But this is personal now.
Me versus the server.
I want to get this thing down to a minute, and I know I still have some optimizations left on the table that I’m not using. I’ve got pride on the line and it’s time to shave every last second I can out of this thing.
Let’s shave a few more seconds off…
Some of the databases don’t actually have a departments dimension but I’m bringing a “dummy” department just so my load rules are all the same — but why bring in a column of data I don’t need? Let’s tweak that load rule to skip that column (as in, don’t even bother to bring it in from SQL) on databases that don’t have the departments dimension. So I tweaked the load rule got the whole process down to 1:51.
Many of these load rules are using text replacements to conform the incoming department to something that is in the outline… well, what if I just setup an alternate alias table so I don’t even have to worry about the text replacements? It stands to reason, from an Essbase data load perspective, that it’s got to cycle through the list of rows on the text replace list and check it against the incoming data, so if I can save it the trouble of doing that, it just might go faster. And indeed it does: 1:39 (one minute, thirty nine seconds). I don’t normally advocate just junking up the outline with extra alias tables, but it turns out that I already had an extra one in there that was only being used for a different dimension, so I added my “convenience” aliases to that. I’m getting close to that minute mark, but of course now I’m just shaving tiny bits off the overall time.
At this point, many of the steps in the 90-step profiling process are taking between 0 and 1 seconds (which is kind of funny, that a single step starts, processes, and finishes in .3 seconds or something), but several of them stand out and take a bit longer. What else?
I tried playing with Zlib compression, thinking that maybe if I could shrink the amount of data on disk, I could read it faster into memory. In all cases this seemed to hurt performance a bit so I went back to bitmap. I have used Zlib compression quite successfully before, but there’s probably an overhead hit I’m taking for using it on relatively “small” database — in this case I need to get in and get out as fast as I can and bitmap seems to allow me to do that just a little faster, so no Zlib this time around (but I still love you Zlib, no hard feelings okay?).
Okay, what ELSE? I decided to bump the threads on load to 8 to see if I got more of a boost — I did. Total load time is now at 1:25.
The SQL data load using bcp (the bulk load command line program) takes up a good 10 seconds or so, and I was wondering if I could boost this a bit. bcp lets you tweak the size of the packets, number of rows per batch, and lock the table you’re loading to. So I tweaked the command line to use these options, and killed another few seconds off the process — down to 1:21.
Now what? It turns out that my Location dimension is relatively flat, with just two aggregated members in it. I decided that I don’t really need to calculate these and setting them as dynamic would be feasible. Since location is dense this has the added benefit of removing two members from my stored data block, or about 10 percent in this case. I am definitely approaching that area where I am possibly trading query performance just for a little bit faster load, but right now I don’t think I’m trading away any noticeable performance on the user side (these databases are relatively small).
Just reducing the data blocks got me down to 1:13 or so (closer!), but since there are now no aggregating members that are stored in the Location dimension, I don’t even need to calculate this dimension at all — so I took the CALC DIMs out of all the calc scripts and got my calc time down further to about 1:07.
Where oh where can I find just 7 more seconds to shave off? Well, some of these databases also have a flat department structure, so I can definitely shave a few seconds and save myself the trouble of having to aggregate the departments dimension by also going to a dynamic calc on the top level member. So I did this where I could, and tweaked the calcs accordingly and now the automation is down to about 1:02.
And I am seriously running out of ideas as to where I can shave just a COUPLE of more seconds off. Come on Scotty, I need more power!
Well, keeping in mind that this is a period process that runs numerous times during closing week, part of this process is to clear out the data for the current period and load in the newer data. Which means that every database has a “clear” calc script somewhere. I decided to take a look at these and see if I could squeeze a tiny bit of performance out.
I wanted to use CLEARBLOCK because I’ve used that for good speedups before, but it’s not really effective as a speedup here because I have a dense time dimension and don’t want to get rid of everything in it (and I think CLEARBLOCK just reverts to a normal CLEARDATA if it can’t burn the whole block). However, there were still some opportunities to tweak the clearing calc script a little so that it was more conducive to the new dense and sparse settings. And sure enough, I was able to shave .1 or .2 seconds off of the clear calc on several databases, giving me a total process time of……. 59.7 seconds. Made it, woot!
Along the way I tried several other tweaks here and there but none of them gave me a noticeable performance gain. One change I also made but seems to be delivering sporadic speed improvements is to resize the index caches to accommodate the entire index file. Many of the indexes are less than 8 megabytes already so they’re fine in that regard, some of them aren’t so I sized them accordingly. I’d like to believe that keeping the index in memory is contributing to better performance overall but I just haven’t really been able to profile very well.
After all that, in ideal circumstances, I got this whole, previously hour-and-a-half job down to a minute. That’s not bad. That’s not bad at all. Sadly, my typical process time is probably going to be a minute or two or longer as I adjust the automation to include more safety checks and improve robustness as necessary. But this is still a vast improvement. The faster turnaround time will allow my users to have more accurate data, and will allow me to turn around the databases faster if something goes wrong or I need to change something and update everything. In fact, this came in extremely useful today while I was researching some weird variances against the financial statements. I was able to make a change, reprocess the databases in a minute or so, and see if my change fixed things. Normally I’d have to wait an hour or more to do that. I may have optimized more than I needed to (because I have an almost unhealthy obsession with performance profiling and optimization), but I think it was worth it. The automation runs fast.
So, my advice to you: always look at the big picture, don’t be afraid to use a different technology, get metrics and refer to them religiously (instead of “hmm, I think it’s faster this way), try to think like Essbase — and help it do its job faster, and experiment, experiment, experiment. Continue Reading…
The %COMPUTERNAME%/MaxL trick for syncing test to production
There’s an automation trick I’ve been using for awhile that I like. Having talked about automation and such with other people at ODTUG this year, it seems that several people are using this technique or a variant of it on their own systems.
Basically, the idea is that you want to be able to sync your production automation scripts from your test server as easily as possible. The number one cause of scripts not working after copying them from test to production is because they have some sort of hard-coded path, filename, server name, user id, password, or other value that simply doesn’t work on the server you are dropping your scripts onto.
Therefore, you want to try and write your automation scripts as generically as possible, and use variables to handle anything that is different between test and production. As an added bonus for making the sync from test to prod just a little bit easier, why not dynamically choose the proper configuration file?
Assuming you are running on Windows (the same concept will work on other platforms with some tweaks for your local scripting environment), one way to handle it is like this: your main script is main.bat (or whatever). One of the environment variables on a windows server is the COMPUTERNAME variable. Let’s say that your test server is essbase30 and your production server is essbase10. On the production server, COMPUTERNAME is essbase10.
Knowing that we can set environment variables in a batch file that will be available in MaxL, we could setup a file called essbase30.bat that has all of our settings for when the script runs on that server. For example, the contents of essbase30.bat might be this:
SET ESSUSR=admin SET ESSPW=password SET ESSSERVER=essbase30
From main.bat, we could then do this:
cd /d %~dp0 call %COMPUTERNAME%.bat essmsh cleardb.msh
Assuming that the two batch files and the cleardb.msh are in the same folder, cleardb.msh could contain the following MaxL:
login $ESSUSR identified by $ESSPW on $ESSSERVER; alter database Sample.Basic reset data; logout; exit;
Now for a little explanation. Note that in essbase30.bat I am explicitly setting the name of the server. We could assume that this is localhost or the COMPUTERNAME but why not set it here so that if we want to run the script against a remote server, we could do that as well (note that if we did run it remotely, we’d have to change the name of our batch file to match the name of the server running the script). In general, more flexibility is a good thing (don’t go overboard though). The first line of main.bat (the cd command) is simply a command to change the current directory to the directory containing the script. This is handy if our script is launched from some other location — and using this technique we don’t have to hard-code a particular path.
Then we use a call command in the batch file to run the batch file named %COMPUTERNAME%.bat, where %COMPUTERNAME% will be replaced with the name of the computer running the automation, which is in this case essbase30. The batch file will run, all of the SET commands inside it will associate values to those environment variables, and control flow will return to the calling batch file, which then calls essmsh to run cleardb.msh (note that essmsh should be in your current PATH for this to work). The file cleardb.msh then runs and can “see” the environment variables that we set in essbase30.bat.
If we want to, we can set variables for folder names, login names, SQL connection names/passwords, application names, and database names. Using this technique can make your MaxL scripts fairly portable and more easily reusable.
In order to get this to work on the production server, we could just create another batch file called essbase10.bat that has the same contents as essbase30.bat but with different user names and passwords or values that are necessary for that server.
For all you advanced batch file scripters out there, it may be necessary to use a setlocal command so the variables in the batch file don’t stomp on something you need that is already an environment variable. As you can see, I’m a big fan of the %COMPUTERNAME% technique, however, there are a few things to watch out for:
- You might be putting passwords in clear text in a batch file. You can alleviate some of this by using MaxL encryption, although I haven’t actually done this myself. The folder with these files on my servers already have filesystem level security that prevent access, and for the time being, this has been deemed good enough.
- It’s difficult with this technique to run automation for test and prod from the same server (say, some central scheduling server). It’s not too difficult to address this, though.
- If you run the automation from a remote server instead of the Essbase server itself, you may end up with lots of different config files — in which case, you might want to adjust this technique a bit.
As for deploying your test files to your production server, if you’ve set everything up in a generic way, then simply changing the variables in the configuration file should allow you to run the exact same script on each server. Therefore, your deploy method could literally be as simple as copying the folder from the test server to the production server. I’m actually using Subversion to version control the automation systems now, but a simple file copy also works just as well
Remote server automation with MaxL
Did you know that you don’t have to run your MaxL automation on the Essbase server itself? Of course, there is nothing wrong with running your Essbase automation on the server: network delays are less of a concern, it’s one less server to worry about, and in many ways, it’s just simpler. But perhaps you have a bunch of functionality you want to leave on a Windows server and have it run against your shiny new AIX server, or you just want all of the automation on one machine. In either case, it’s not too difficult to setup, you just have to know what to look out for.
If you’re used to writing MaxL automation that runs on the server, there are a few things you need to look out for in order to make your automation more location-agnostic. It is possible to specify the locations of rules, reports, and data files all using either a server-context or a client-context. For example, your original automation may have referred to absolute file paths that are only valid if you are on the server. If the automation is running on a different machine then it’s likely that those paths are no longer valid. You can generally adjust the syntax to explicitly refer to files that are local versus files that are remote.
The following example is similar in content to an earlier example I showed dealing with converting an ESSCMD automation system to MaxL. This particular piece of automation will also run just as happily on a client or workstation or remote server (that has the MaxL interpreter, essmsh installed of course). Keeping in mind that if we do run this script on our workstation, however, the entries highlighted in red refer to paths/files on the server, and the text highlighted in green refer to things that are relevant to the client executing the script. So, here is the script:
/* conf includes SET commands for the user, password, server logpath, and errorpath */ msh "conf.msh"; /* Transfer.Data is a "dummy" application on the server that is useful to be able to address text files within a App dot Database context Note that I have included the ../../ prefix because with version 7.1.x of Essbase even though prefixing the file name with a directory separator is supposed to indicate that the path is an app/database path, I can't get it to work, but using ../../ seems to work (even on a Windows server) */ set DATAFOLDER = "../../Transfer/Data"; login $ESSUSER identified by $ESSPW on $ESSSERVER; /* different files for the spool and errors */ spool stdout on to "$LOGPATH/spool.stdout.PL.RefreshOutline.txt"; spool stderr on to "$LOGPATH/spool.stderr.PL.RefreshOutline.txt"; /* update P&L database Note that we are using 3 different files to update the dimensions all at once and that suppress verification is on the first two. This is roughly analogous to the old BEGININCBUILD-style commands from EssCmd */ import database PL.PL dimensions from server text data_file "$DATAFOLDER/DeptAccounts.txt" using server rules_file 'DeptAcct' suppress verification, from server text data_file "$DATAFOLDER/DeptAccountAliases.txt" using server rules_file 'DeptActA' suppress verification, from server text data_file "$DATAFOLDER/DeptAccountsShared.txt" using server rules_file 'DeptShar' preserve all data on error write to "$ERRORPATH/dim.PL.txt"; /* clean up */ spool off; logout; exit;
This is a script that updates dimensions on a fictitious “PL” app/cube. We are using simple dimension build load rules to update the dimensions. Following line by line, you can see the first thing we do is run the “conf.msh” file. This is merely a file with common configuration settings in it that are declared similarly to the following “set” line. Next, we set our own helper variable called DATAFOLDER. While not strictly necessary, I find that it makes the script more flexible and cleans things up visually. Note that although it appears we are using a file path (“../../Transfer/Data”) this actually refers to a location on the server, specifically, it is the app/Transfer/Data path in our Hyperion folder (where Transfer is the name of an application and Data is the name of a database in that application). This is a common trick we use in order to have both a file location as well as a way to refer to files in an Essbase app/db way.
Next, we login to the Essbase server. Again, this just refers to locations that are defined in the conf.msh file. We set our output locations for the spool command. Here is our first real difference when it comes to running the automation on the server versus running somewhere else. These locations are relevant to the system executing the automation — not the Essbase server.
Now on to the import command. Note that although we are using three different rules files and three different input files for those rules files, we can do all the work in one import command. Also note that the spacing and spanning of the command over multiple lines makes it easier for us humans to read — and the MaxL interpreter doesn’t really care one way or another. The first file we are loading in is DeptAccounts.txt, using the rules file DeptAcct.
In other words, here is the English translation of the command: “Having already logged in to Essbase server $ESSSERVER with the given credentials, update the dimensions in the database called PL (in the Application PL), using the rules file named DeptAcct (which is also located in the database PL), and use it to parse the data in DeptAccounts.txt file (which is located in the Transfer/Data folder. Also, suppress verification of the outline for the moment.”
The next two sections of the command do basically the same thing, however we omit the “suppress verification” on the last one so that now the server will validate all the changes for the outline. Lastly, we want to preserve all of the data currently in the cube, and send all rejected data (records that could not be used to update the dimensions) to the dim.PL.txt file (which is located on the machine executing this script, in the $ERRORPATH folder).
So, as you can see, it’s actually pretty simple to run automation on one system and have it take action on another. Also, some careful usage of MaxL variables, spacing, and comments can make a world of difference in keeping things readable. One of the things I really like about MaxL over ESSCMD is that you don’t need a magic decoder ring to understand what the script is trying to do — so help yourself and your colleagues out by putting that extra readability to good use.
MaxL Essbase automation patterns: moving data from one cube to another
A very common task for Essbase automation is to move data from one cube to another. There are a number of reasons you may want or need to do this. One, you may have a cube that has detailed data and another cube with higher level data, and you want to move the sums or other calculations from one to the other. You may accept budget inputs in one cube but need to push them over to another cube. You may need to move data from a “current year” cube to a “prior year” cube (a data export or cube copy may be more appropriate, but that’s another topic). In any case, there are many reasons.
For the purposes of our discussion, the Source cube is the cube with the data already in it, and the Target cube is the cube that is to be loaded with data from the source cube. There is a simple automation strategy at the heart of all these tasks:
- Calculate the source cube (if needed)
- Run a Report script on the source cube, outputting to a file
- Load the output from the report script to the target cube with a load rule
- Calculate the target cube
This can be done by hand, of course (through EAS), or you can do what the rest of us lazy cube monkeys do, and automate it. First of all, let’s take a look at a hypothetical setup:
We will have an application/database called Source.Foo which represents our source cube. It will have dimensions and members as follows:
- Location: North, East, South, West
- Time: January, February, …, November, December
- Measures: Sales, LaborHours, LaborWages
As you can see, this is a very simple outline. For the sake of simplicity I have not included any rollups, like having “Q1/1st Quarter” for January, February, and March. For our purposes, the target cube, Target.Bar, has an outline as follows:
- Scenario: Actual, Budget, Forecast
- Time: February, …, November, December
- Measures: Sales, LaborHours, LaborWages
These outlines are similar but different. This cube has a Scenario dimension with Actual, Budget, and Forecast (whereas in the source cube, since it is for budgeting only, everything is assumed to be Budget). Also note that Target.Bar does not have a Location dimension, instead, this cube only concerns itself with totals for all regions. Looking back at our original thoughts on automation, in order for us to move the data from Source.Foo to Target.Bar, we need to calculate it (to roll-up all of the data for the Locations), run a report script that will output the data how we need it for Target.Bar, use a load rule on Target.Bar to load the data, and then calculate Target.Bar. Of course, business needs will affect the exact implementation of this operation, such as the timing, the calculation to use, and other complexities that may arise. You may actually have two cubes that don’t have a lot in common (dimensionally speaking), in which case, your load rule might need to really jump through some hoops.
We’ll keep this example really simple though. We’ll also assume that the automation is being run from a Windows server, so we have a batch file to kick things off:
cd /d %~dp0 essmsh ExportAndLoadBudgetData.msh
I use the cd /d %~dp0 on some of my systems as a shortcut to switch the to current directory, since the particular automation tool installed does not set the home directory of the file to the current working directory. Then we invoke the MaxL shell (essmsh, which is in the PATH) and run ExportAndLoadBudgetData.msh. I enjoy giving my automation files unnecessarily long filenames. It makes me feel smarter.
As you may have seen from an earlier post, I like to modularize my MaxL scripts to hide/centralize configuration settings, but again, for the sake of simplicity, this example will forgo that. Here is what ExportAndLoadBudgetData.msh could look like:
/* Copies data from the Budget cube (Source.Foo) to the Budget Scenario of Target.Bar */
/* your very standard login sequence here */ login AdminUser identified by AdminPw on EssbaseServer;
/* at this point you may want to turn spooling on (omitted here) */
/* disable connections to the application -- this is optional */
alter application Source disable connects;
/* PrepExp is a Calc script that lives in Source.Foo and for the purposes
of this example, all it does is makes sure that the aggregations that are
to be exported in the following report script are ready. This may not be
necessary and it may be as simple as a CALC ALL; */
execute calculation Source.Foo.PrepExp;
/* Budget is the name of the report script that runs on Source.Foo and outputs a
text file that is to be read by Target.Bar's LoadBud rules file */
export database Source.Foo
using report_file 'Budget'
to data_file 'foo.txt';
/* enable connections, if they were disabled above */
alter application Source enable connects;
/* again, technically this is optional but you'll probably want it */
alter application Target disable connects;
/* this may not be necessary but the purpose of the script is to clear out
the budget data, under the assumption that we are completely reloading the
data that is contained in the report script output */
execute calculation Target.Bar.ClearBud;
/* now we import the data from the foo.txt file created earlier. Errors
(rejected records) will be sent to errors.txt */
import database Target.Bar data
from data_file 'foo.txt'
using rules_file 'LoadBud'
on error write to 'errors.txt';
/* calculate the new data (may not be necessary depending on what the input
format is, but in this example it's necessary */
execute calculation Target.Bar.CalcAll;
/* enable connections if disabled earlier */
alter application Target enable connects;
/* boilerplate cleanup. Turn off spooling if turned on earlier */ logoff; exit;
At this point , if we don’t have them already, we would need to go design the aggregation calc script for Source.Foo (PrepExp.csc), the report script for Source.Foo (Budget.rep), the clearing calc script on Target.Bar (ClearBud.csc), the load rule on Target.Bar (LoadBud.rul), and the final rollup calc script (CalcAll.csc). Some of these may be omitted if they are not necessary for the particular process (you may opt to use the default calc script, may not need some of the aggregations, etc).
For our purposes we will just say that the PrepExp and CalcAll calc scripts are just a CALC ALL or the default calc. You may want a “tighter” calc script, that is, you may want to design the calc script to run faster by way of helping Essbase understand what you need to calculate and in what order.
What does the report script look like? We just need something to take the data in the cube and dump it to a raw text file.
<ROW ("Time", "Measures")
{ROWREPEAT}
{SUPHEADING}
{SUPMISSINGROWS}
{SUPZEROROWS}
{SUPCOMMAS}
{NOINDENTGEN}
{SUPFEED}
{DECIMAL 2}
<DIMBOTTOM "Time"
<DIMBOTTOM "Measures"
"Location"
!
Most of the commands here should be pretty self explanatory. If the syntax looks a little different than you’re used to, it’s probably because you can also jam all of the tokens in one line if you want like {ROWREPEAT SUPHEADING} but historically I’ve had them one to a line. If there were more dimensions that we needed to represent, we’d put thetm on the <ROW line. As per the DBAG, we know that the various tokens in between {}’s format the data somehow — we don’t need headings, missing rows, rows that are zero (although there are certainly cases where you might want to carry zeros over), no indentation, and numbers will have two decimal places (instead of some long scientific notation). Also, I have opted to repeat row headings (just like you can repeat row heading in Excel) for the sake of simplicity, however, as another optimization tip, this isn’t necessary either — it just makes our lives easier in terms of viewing the text file and loading it to a SQL database or such.
As I mentioned earlier, we didn’t have rollups such as different quarters in our Time dimension. That’s why we’re able to get away with using <DIMBOTTOM, but if we wanted just the Level 0 members (the months, in this case), we could use the appropriate report script. Lastly, from the Location dimension we are taking use the Location member (whereas <DIMBOTTOM “Time” tells Essbase to give us all the members to the bottom of the Time dimension, simply specifying a member or members from the dimension will give us those members), the parent to the different regions. “Location” will not actually be written in the output of the report script because we don’t need it — the outline of Target.Bar does not have a location dimension since it’s implied that it represents all locations.
The output of the report script will look similar to the following:
January Sales 234.53 January LaborHours 35.23 February Sales 532.35
From here it is a simple matter of designing the load rule to parse the text file. In this case, the rule file is part of Target.Bar and is called LoadBud. If we’ve designed the report script ahead of time and run it to get some output, we can then go design the load rule. When the load rule is done, we should be able to run the script (and schedule it in our job scheduling software) to carry out the task in a consistent and automated manner.
As an advanced topic, there are several performance considerations that can come into play here. I already alluded to the fact that we may want to tighten up the calc scripts in order to make things faster. In small cubes this may not be worth the effort (and often isn’t), but as we have more and more data, designing the calc properly (and basing it off of good dense/sparse choices) is critical. Similarly, the performance of the report script is also subject to the dense/sparse settings, the order of the output, and other configuration settings in the app and database. In general, what you are always trying to do (performance wise) is to help the Essbase engine do it’s job better — you do this by making the tasks you want to perform more conducive to the way that Essbase processes data. In other words, the more closely you can align your data processing to the under-the-hood mechanisms of how Essbase stores and manipulates your data, the better off you’ll be. Lastly, the load rule on the Target database, and the dense/sparse configurations of the Target database, will impact the data load performance. You may not and probably will not be able to always optimize everything all at once — it’s a balancing act — since a good setting for a report script may result in suboptimal calculation process. But don’t let this scare you — try to just get it to work first and then go in and understand where the bottlenecks may be.
As always, check the DBAG for more information, it has lots of good stuff in it. And of course, try experimenting on your own, it’s fun, and the harder you have to work for knowledge, the more likely you are to retain it. Good luck out there!
A quick and dirty substitution variable updater
There are a lot of different ways to update your substitution variables. You can tweak them with EAS by hand, or use one of several different methods to automate it. Here is one method that I have been using that seems to hit a relative sweet spot in terms of flexibility, reuse-ability, and effectiveness.
First of all, why substitution variables? They come in handy because you can leave your Calc and Report scripts alone, and just change the substitution variable to the current day/week/month/year and fire off the job. You can also use them in load rules. You would do this if you only want to load in data for a particular year or period, or records that are newer than a certain date, or something similar.
The majority of my substitution variables seem to revolve around different time periods. Sometimes the level of granularity is just one period or quarter (and the year of the current period, if in a separate Years dimension), and sometimes it’s deeper (daily, hourly, and so on).
Sure, we could change the variables ourselves, manually, but where’s the fun in that? People that know me know that I have a tendency to automate anything I can, although I still try to have respect for what we have come to know as “keeping an appropriate level of human intervention” in the system. That being said, I find that automating updates to timing variables is almost always a win.
Many organizations have a fiscal calendar that is quite different than a typical (“Gregorian”) calendar with the months January through December. Not only can the fiscal calendar be quite different, it can have some weird quirks too. For example, periods may have only four weeks one year but have five weeks in other years, and on top of that, there is some arcane logic used to calculate which is which (well, it’s not really arcane, it just seems that way). The point is, though, that we don’t necessarily have the functionality on-hand that converts a calendar date into a fiscal calendar date.
One approach to this problem would be to simply create a data file (or table in a relational database, or even an Excel sheet) that maps a specific calendar date to its equivalent fiscal date counterparts. This is kind of the “brute-force” approach, but it works, and it’s simple. You just have to make sure that someone remembers to update the file from year to year.
For example, for the purposes of the date “December 22, 2008” in a cube with separate years, time, and weekday dimensions, I need to know three things: the fiscal year (probably 2008), the fiscal period (we’ll say Period 12 for the sake of simplicity, and the day of the week: day “2”). Of course, this can be very different across different companies and organizations. Monday might be the first day of the week or something. If days are included in the Time dimension, we don’t really need a separate variable here. So, the concepts are the same but the implementation will look different (as with everything in Essbase, right?).
I want something a bit “cleaner,” though. And by cleaner, I mean that I want something algorithmic to convert one date to another, not just a look-up table. Check with the Java folks in your company, if you’re lucky then they may already have a fiscal calendar class that does this for you. Or it might be Visual Basic, or C++, or something else. But, if someone else did the hard work already, then by all means, don’t reinvent the wheel.
Here is where the approaches to updating variables start to differ. You could do the whole thing in Java, updating variables with the Java API. You could have a fancy XML configuration file that is interpreted and tells the system what variables to create, where to put them, and so on. In keeping with the KISS philosophy, though, I’m going to leave the business logic separate from the variable update mechanism. Meaning this: in this case I will use just enough program code to generate the variables, then output them to a space-delimited file. I will then have a separate process that reads the file and updates the Essbase server. One of the other common approaches here would be to simply output MaxL or ESSCMD script itself, then run the file. This works great too, however, I like having “vanilla” files that I can load in to other programs if needed (or, say, use in a SQL Server DTS/SSIS job).
At the end of the day, I’ve generated a text file with conents like this:
App1 Db1 CurrentYear 2008 App1 Db1 CurrentPeriod P10 App1 Db1 CurrentWeek Week4 App2 Db1 CurrentFoo Q1
Pretty simple, right? Note that this simplified approach is only good for setting variables with a specific App/database. It needs to be modified a little to set global substitution variables (but I’m sure you are enterprising enough to figure this out — check the tech ref for the appropriate MaxL command).
At this point we could setup a MaxL script that takes variables on the command line and uses them in its commands to update the corresponding substitution variable, but there is also another way to do this: We can stuff the MaxL statement into our invocation of the MaxL shell itself. In a Windows batch file, this whole process looks like this:
SET SERVER=essbaseserver SET USER=essbaseuser SET PW=essbasepw REM generates subvar.conf file REM this is your call to the Java/VB/C/whatever program that REM updates the variable file subvarprogram.exe REM this isn't strictly needed but it makes me feel better sleep 2 REM This is batch code to read subvar.conf's 4 fields and pipe REM them into a MaxL session REM NOTE: this is ONE line of code but may show as multiple in REM your browser! FOR /f "eol=; tokens=1,2,3,4 delims=, " %%i in (subvar.conf) do echo alter database %%j.%%k set variable %%i %%l; | essmsh -s %SERVER% -l %USER% %PW% -i REM You would use the below statement for the first time you need REM to initialize the variables, but you will use the above statement REM for updates to them (you can also just create the variables in REM EAS) REM FOR /f "eol=; tokens=1,2,3,4 delims=, " %%i in (subvar.conf) do echo alter database %%j.%%k add variable %%i; | essmsh -s %SERVER% -l %USER% %PW% -i
Always remember — there’s more than one way to do it. And always be mindful of keeping things simple — but not too simple. Happy holidays, ya’ll.
MaxL tricks and strategies on upgrading a legacy automation system from ESSCMD
The Old
In many companies, there is a lot of code laying around that is, for lack of better word, “old.” In the case of Essbase-related functionality, this may mean that there are some automation systems with several ESSCMD scripts laying around. You could rewrite them in MaxL, but where’s the payoff? There is nothing inherently bad with old code, in fact, you can often argue a strong case to keep it: it tends to reflect many years of tweaks and refinements, is well understood, and generally “just works” — and even when it doesn’t you have a pretty good idea where it tends to break.
Rewrite it?
That being said, there are some compelling reasons to do an upgrade. The MaxL interpreter brings a lot to the table that I find incredibly useful. The existing ESSCMD automation system in question (essentially a collection of batch files, all the ESSCMD scripts with the .aut extension, and some text files) is all hard-coded to particular paths. Due to using absolute paths with UNC names, and for some other historical reasons, there only exists a production copy of the code (there was perhaps a test version at some point, but due to all of the hard-coded things, the deployment method consisted of doing a massive search and replace operation in a text editor). Because the system is very mature, stable, and well-understood, it has essentially been “grandfathered” in as a production system (it’s kind of like a “black box” that just works).
The Existing System
The current system performs several different functions across its discreet job files. There are jobs to update outlines, process new period data, perform a historical rebuild of all cubes (this is currently a six hour job and in the future I will show you how to get it down to a small fraction of its original time), and some glue jobs that scurry data between some different cubes and systems. The databases in this system are setup such that there are about a dozen very similar cubes. They are modeled on a series of financial pages, but due to differences in the way some of the pages work, it was decided years ago that the best way to model cubes on the pages was to split them up in to different sets of cubes, rather than one giant cube. This design decision had paid off in many ways. One, it keeps the cubes cleaner and more intuitive; interdimensional irrelevance is also kept to a minimum. Strategic dense/sparse settings and other outline tricks like dynamic calcs in the Time dimension rollups also keep things pretty tight.
Additionally, since the databases are used during the closing period, not just after (for reporting purposes), new processes can go through pretty quickly and update the cubes to essentially keep them real-time with how the accounting allocations are being worked out. Keeping the cubes small allows for a lot less down-time (although realistically speaking, even in the middle of a calc, read-access is still pretty reliable).
So, first things first. Since there currently are no test copies of these “legacy” cubes, we need to get these setup on the test server. This presents a somewhat ironic development step: using EAS to copy the apps from the production server, to the development server. These cubes are not spun up from EIS metaoutlines, and there is very little compelling business reason to convert them to EIS just for the sake of converting them, so this seems to be the most sensible approach.
Although the outlines are in sync right now between production and development because I just copied them, the purpose of one of the main ESSCMD jobs is to update the outlines on a period basis, so this seems like a good place to start. The purpose of the outline update process is basically to sync the Measures dimension to the latest version of the company’s internal cross-reference. The other dimensions are essentially static, and only need to be updated rarely (e.g., to add a new year member). The cross-reference is like a master list of which accounts are on which pages and how they aggregate.
On a side note, the cross-reference is part of a larger internal accounting system. What it lacks in flexibility, it probably more than makes up for with reliability and a solid ROI. One of the most recognized benefits that Essbase brings to the table in this context is a completely new and useful way of analyzing existing data (not to mention write-back functionality for budgeting and forecasting) that didn’t exist. Although Business Objects exists within the company too, it is not recognized as being nearly as useful to the internal financial customers as Essbase is. I think part of this stems from the fact that BO seems to be pitched more to the IT crowd within the organization, and as such, serves mostly as a tool to let them distribute data in some fashion, and call it a day. Essbase really shines, particularly because it is aligned with the Finance team, and it is customized (by finance team members) to function as a finance tool, versus just shuttling gobs of data from the mainframe to the user.
The cross-reference is parsed out in an Access database in order to massage the data into various text files that will serve as the basis of dimension build load rules for all the cubes. I know, I know, I’m not a huge Access fan either, but again, the system has been around forever, It Just Works, and I see no compelling reason to upgrade this process, to say, SQL Server. Because of how many cubes there are, different aliases, different rollups, and all sorts of fun stuff, there are dozens of text files that are used to sync up the outlines. This has resulted in some pretty gnarly looking ESSCMD scripts. They also use the BEGININCBUILD and ENDINCBUILD ESSCMD statements, which basically means that the cmd2mxl.exe converter is useless to us. But no worries — we want to make some more improvements besides just doing a straight code conversion.
In a nutshell, the current automation script logs in (with nice hard-coded server path, user name, and password, outputs to a fixed location, logs in to each database in sequence, and has a bunch of INCBUILDDIM statements. ESSCMD, she’s an old girl, faithful, useful, but just not elegant. You need a cheatsheet to figure out what the invocation parameters all mean. I’ll spare you the agony of seeing what the old code looks like.
Goals
Here are my goals for the conversion:
- Convert to MaxL. As I mentioned, MaxL brings a lot of nice things to the table that ESSCMD doesn’t provide, which will enable some of the other goals here.
- Get databases up and running completely in test — remember: the code isn’t bad because it’s old or “legacy code,” it’s just “bad” because we can’t test it.
- Be able to use same scripts in test as in production. The ability to update the code in one place, test it, then reliably deploy it via a file-copy operation (as opposed to hand-editing the “production” version) is very useful (also made easier because of MaxL).
- Strategically use variables to simplify the code and make it directory-agnostic. This will allow us to easily adapt the code to new systems in the future, for example, if we want to consolidate to a different server in the future, even one on a different operating system).
- And as a tertiary goal: Start using a version control system to manage the automation system. This topic warrants an article all on itself, which I fully intend to write in the future. In the meantime, if you don’t currently use some type of VCS, all you need to know about the implications of this are that we will have a central repository of the automation code, which can be checked-in and checked-out. In the future we’ll be able to look at the revision history of the code. We can also use the repository to deploy code to the production server. This means that I will be “checking-out” the code to my workstation to do development, and I’m also going to be running the code from my workstation with a local copy of the MaxL interpreter. This development methodology is made possible in part because in this case, my workstation is Windows, and so are the Essbase servers.
For mostly historical reasons the old code has been operated and developed on the analytic server itself, and there are various aspects about the way the code has been developed that mean you can’t run it from a remote server. As such, there are various semantic client/server inconsistencies in the current code (e.g. in some cases we are referring to a load rule by it’s App/DB context, and in some cases we are using an absolute file path). Ensuring that the automation works from a remote workstation will mean that these inconsistencies are cleaned up, and if we choose to move the automation to a separate server in the future, it will be much easier.
First Steps
So, with all that out of the way, let’s dig in to this conversion! For the time being we’ll just assume that the versioning system back-end is taken care of, and we’ll be putting all of our automation files in one folder. The top of our new MaxL file (RefreshOutlines.msh) looks like this:
msh "conf.msh"; msh "$SERVERSETTINGS";
What is going on here? We’re using some of MaxL features right away. Since there will be overlap in many of these automation jobs, we’re going to put a bunch of common variables in one file. These can be things like folder paths, app/database names, and other things. One of those variables is the $SERVERSETTINGS variable. This will allow us to configure a variable within conf.msh that points to where the server-specific MaxL configuration file. This is one method that allows us to centralize certain passwords and folder paths (like where to put error files, where to put spool files, where to put dataload error files, and so on). Configuring things this way gives us a lot of flexibility, and further, we only really need to change conf.msh in order to move things around — everything else builds on top of the core settings.
Next we’ll set a process-specific configuration variable which is a folder path. This allows us to define the source folder for all of the input files for the dimension build datafiles.
SET SRCPATH = "../../Transfer/Data";
Next, we’ll log in:
login $ESSUSER identified by $ESSPW on $ESSSERVER;
These variables are found in the $SERVERSETTINGS file. Again, this file has the admin user and password in it. If we needed more granularity (i.e., instead of running all automation as the god-user and instead having just a special ID for the databases in question), we could put that in our conf.msh file. As it is, there aren’t any issues on this server with using a master ID for the automation.
spool stdout on to "$LOGPATH/spool.stdout.RefreshOutlines.txt"; spool stderr on to "$LOGPATH/spool.stderr.RefreshOutlines.txt";
Now we use the spooling feature of MaxL to divert standard output and error output to two different places. This is useful to split out because if the error output file has a size greater than zero, it’s a good indicator that we should take a look and see if something isn’t going as we intended. Notice how we are using a configurable LOGPATH directory. This is the “global” logpath, but if we wanted it somewhere else we could have just configured it that way in the “local” configuration file.
Now we are ready for the actual “work” in this file. With dimension builds, this is one of the areas where ESSCMD and MaxL do things a bit differently. Rather than block everything out with begin/end build sections, we can jam all the dimension builds into one statement. This particular example has been modified from the original in order to hide the real names and to simplify it a little, but the concept is the same. The nice thing about just converting the automation system (and not trying to fix other things that aren’t broken — like moving to an RDBMS and EIS) is that we get to keep all the same source files and the same build rules.
import database Foo.Bar dimensions from server text data_file "$SRCPATH/tblAcctDeptsNon00.txt" using server rules_file 'DeptBld' suppress verification, from server text data_file "$SRCPATH/tblDept00Accts.txt" using server rules_file 'DeptBld' preserve all data on error write to "$ERRORPATH/JWJ.dim.Foo.Bar.txt";
In the actual implementation, the import database blocks go on for about another dozen databases. Finally, we finish up the MaxL file with some pretty boilerplate stuff:
spool off; logout; exit;
Note that we are referring to the source text data file in the server context. Although you are supposed to be able to use App/database naming for this, it seems that on 7.1.x, even if you start the filename with a file separator, it still just looks in the folder of the current database. I have all of the data files in one place, so I was able to work around this by just changing the SRCPATH variable to go up two folders from the current database, then back down into the Transfer\Data folder. The Transfer\Data folder is under the Essbase app\ folder. It’s sort of a nexus folder where external processes can dump files because they have read/write access to the folder, but it’s also the name of a dummy Essbase application (Transfer) and database (Data) so we can refer to it and load data from it, from an Essbase-naming perspective. It’s a pretty common Essbase trick. We are also referring to the rules files from a server context. The output files are to a local location. This all means that we can run the automation from some remote computer (for testing/development purposes), and we can run it on the server itself. It’s nice to sort of “program ahead” for options we may want to explore in the future.
For the sake of completeness, when we go to turn this into a job on the server, we’ll just use a simple batch file that will look like this:
cd /d %~dp0 essmsh RefreshOutlines.msh
The particular job scheduling software on this server does not run the job in the current folder of the job, therefore we use cd /d %~dp0 as a Windows batch trick to change folders (and drives if necessary) to the folder of the current file (that’s what %~dp0 expands out to). Then we run the job (the folder containing essmsh is in our PATH so we can run this like any other command).
All Done
This was one of the trickier files to convert (although I have just shown a small section of the overall script). Converting the other jobs is a little more straightforward (since this is the only one with dimension build stuff in it), but we’ll employ many of the same concepts with regard to the batch file and the general setup of the MaxL file.
How did we do with our goals? Well, we converted the file to MaxL, so that was a good start. We copied the databases over to the test server, which was pretty simple in this case. Can we use the same scripts in test/dev and production? Yes. Since the server specific configuration files will allow us to handle any folder/username/password issues that are different between the servers, but the automation doesn’t care (it just loads the settings from whatever file we tell it), I’d say we addressed this just fine. We used MaxL variables to clean things up and simplify — this was a pretty nice cleanup over the original ESSCMD scripts. And lastly, although I didn’t really delve into it here, this was all developed on a workstation (my laptop) and checked in to a Subversion repository, further, the automation all runs just fine from a remote client. If we ever need to move some folders around, change servers, or make some other sort of change, we can probably adapt and test pretty quickly.
All in all, I’d say it was a pretty good effort today. Happy holidays ya’ll.