Just a quick announcement, SeaHUG is getting together in a couple of weeks for a casual meetup to network, discuss projects, EPM 11.1.2.4, and more. The meetup is going to be at a little brewpub north of downtown. If you’re in the Seattle area swing by and meet up!
Author Archives: jason
cubus outperform EV Analytics Review: Background

As you readers know well by now (and judging by having been posting to this blog for over half a decade), I certainly seem to enjoy all things Essbase (and ODI, and Java, and mobile, and more…). In addition to writing my own software for making Essbase even better, one thing I’d like to do more of is review and offer some thoughts on other software that works with or otherwise enhances Essbase.
To that end, I am pleased to do this review of cubus outperform EV Analytics. This review will occur in three parts:
- Background (this posting)
- Using cubus EV
- Position in the Enterprise
For short I’ll just refer to this software as EV or cubus EV. So, just what is EV? Think of it as a front-end to Essbase. I think you really just have to use EV to get an appreciation for how it works and what it can do, but I’m going to do my best to describe it.
What is it?
Most or all of you reading this should be familiar with how the Excel add-in and Smart View works. Consider the typical ad hoc experience in Smart View and Excel. Now imagine that you want to recreate the ad hoc experience and completely polish and refine every aspect of it, including the user interface, user experience, and just for good measure, add in some really slick features. Now you have EV. Think of EV as trading in some of the freeform nature of Excel in exchange for a more fluid user experience.
This might not seem like a big deal, but to someone such as myself that likes to approach software with an artisan and craftsmanship mentality, it really resonates.
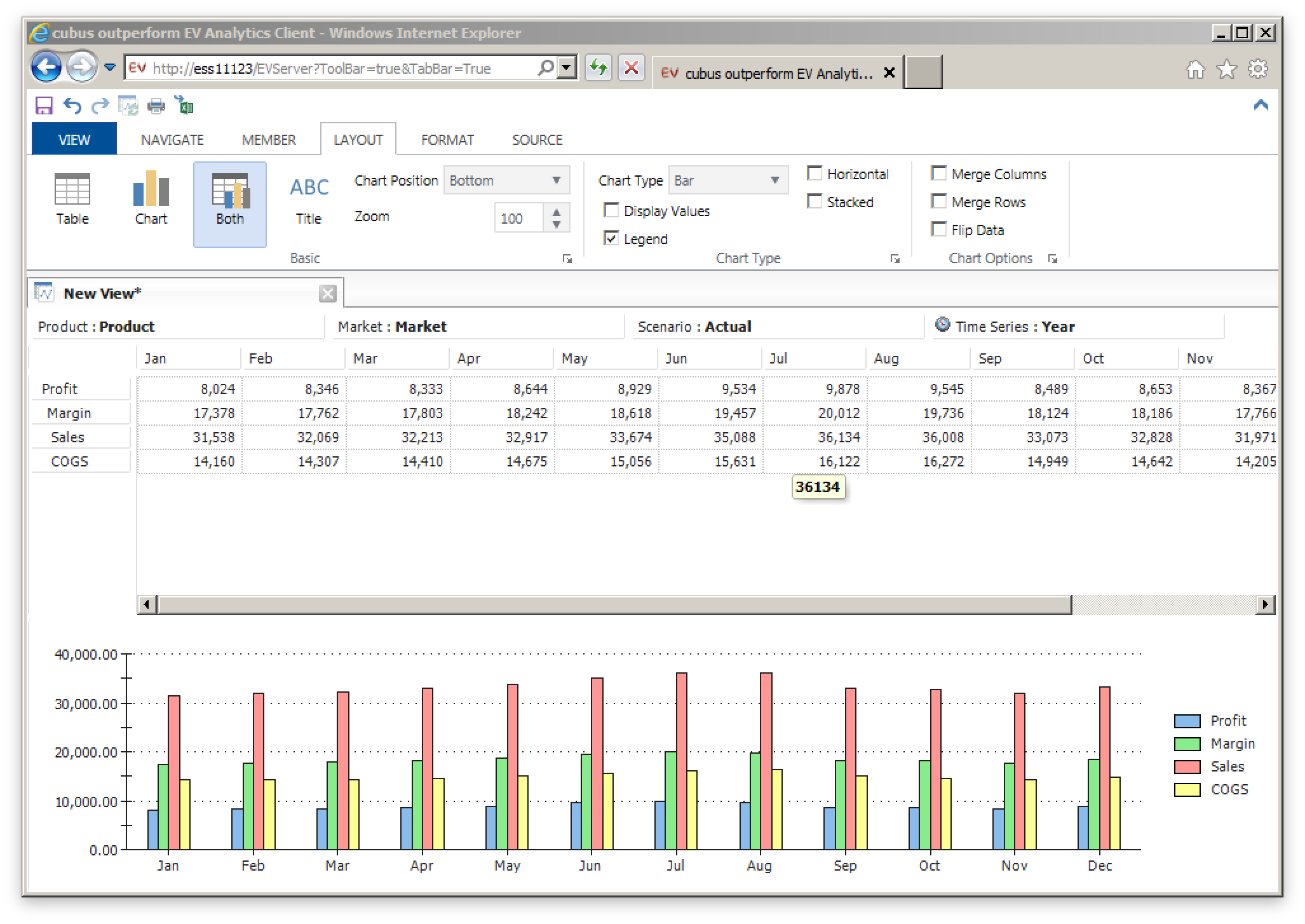
Chart and data shown at the same time (the ‘Both’ option)
Personal History with EV
I first got introduced to EV – then called Executive Viewer – back in 2005 while working for the then smallest subsidiary of best grocer on the planet. As luck would have it, my controller/CFO had fallen in love with the product at his previous company, and one of our other divisions happened to have a spare license to EV just sitting around – so we transferred it over and got up and running. At the time, EV was owned and marketed by a company called Temtec.
Now, I’m a little fuzzy on all this, but my first experience with EV was that it was sold by and supported by Temtec. There seemed to be a sequence of acquisitions and Temtec was gobbled up by Applix, which was gobbled up by Cognos, and then IBM. IBM didn’t seem to otherwise have any major plans for this curious spoil of corporate war, but along came cubus to buy it out and resurrect it. All of this leads us up to now: In the United States, EV is sold through Decision Systems. Elsewhere, it is available through cubus.
Please check back tomorrow for Part 2: Using cubus EV
Drillbridge on Linux

Did I mention recently that Drillbridge can now be installed on Linux in addition to Windows (in fact, Drillbridge is so flexible, it now runs on Windows, Linux, Mac OS X, and AIX all out of the box!). WELL IT DOES!
So regardless if your Hyperion environment is running on Windows, Linux, or AIX, it’s now easier than ever to add Drillbridge to one of your servers and unlock the power of your detailed data for your users.
Kscope15 – Two Presentations
Just wanted to mentioned that I’ll be at Kscope15 (you have registered, haven’t you?) with two brand new presentations. I will be presenting on Drillbridge, the innovative, awesome, easy to implement, super cool, fun, free, and fast drill-through solution, as well as a really interesting twist on an ODI feature.
For the ODI presentation I will be doing a super detailed, incredibly deep dive on one of the main features of ODI – mappings and interfaces – and how they work under the hood, how to make/customize Knowledge Modules, and more. I’m really excited for this presentation because it’s a total nerd look at how and why things are setup the way they are, filtered through the lens of a computer scientist (with a nice helping of cube geekery). I don’t seem to get to write about ODI as much as I write about Hyperion-related things, but truth be told if I had to rate my Oracle-specific skills in order of strength, it would go Java, ODI, and then Hyperion. Go figure.
Anyway, get to registering for Kscope as soon as you can; I have a feeling this year’s is going to be the most awesome yet, and when you do, be sure to swing by my presentations and geek out with me and introduce yourself.
Drillbridge 1.5.0 available!
It took a little longer than anticipated (I took some genuine time off over the holiday break), but I am very happy to make Drillbridge version 1.5.0 available to download.
A lot of work has gone into this release. For example:
- You can now drill from columns (!)
- Use your own custom mappings to resolve member names (this is a super cool feature I wrote about earlier and it knocks the pants off of Essbase Studio (as far as I know) by allowing you to write in mappings for your own members that might not have children (for example, a YTD member in the Time dimension)
- Streaming output performance enhanced
- Now generates XLSX files with much better output (not everything is treated as a String – if the column type is DATE or TIME or TIMESTAMP, it gets treated and formatted accordingly)
- Now run Drillbridge from Linux!
- All files included that should allow for running on Windows, Linux, AIX, Solaris, and even Mac OS X
- Java 7 or newer is required! I know this might be an inconvenience but I pretty much had to, and it’s good to get current with Java. Java 1.8/8 should work just fine as well in case you want to go all out
I have done my absolute best to test this version and make sure it doesn’t have any showstopper bugs but there are bound to be issues. There are a few things I know need to be worked on for the inevitable 1.5.1 release. So if you upgrade, please be sure to make backups so you can flip back to 1.3.3 or 1.3.4 or whatever your current version is, in case there’s something broken that you need.
If you have any questions about the new features and how to use them, don’t hesitate to hit up the forums or email. In the coming days I will be adding on to the Drillbridge Wiki with some info about how to set things up in terms of new features. There was recently a lot of spam activity on the wiki that I’m trying to sort out but for now it looks okay.
That all being said, this is the best release of Drillbridge ever and it now contains every feature I originally set out to put in, and then some. There will undoubtedly be some quirks but I look forward to a few point releases to stamp them out. Many or most of the features are from direct user requests, feedback, and ideas, so thanks to everyone.
Happy Drilling.
Essbase Outline Export Parser released
I had a use-case today where I needed to parse an XML file created by the relatively new MaxL command “export outline”. This command generates an XML file for a given cube for either all dimensions or just all dimensions you specify. I just needed to scrape the file for the hierarchy of a given dimension, and that’s exactly what this tool does: pass in an XML file that was generated by export outline, then pass in the name of a dimension, and the output to the console will be a space-indented list of members in the dimension. More information on usage at the Essbase Outline Export Parser GitHub page including sample input, sample output, and command-line usage.
Also note that the venerable Harry Gates has also created something similar that includes a GUI in addition to working on the command line. While both written in Java, we’re using different methods to parse the XML. Since I’m more familiar/comfortable with JAXB for reading XML I went with that, which in my experience gives a nice clean and extensible way to model the XML file and read it without too much trouble. The code for this project could be easily extended to provide other output formats.
Camshaft 1.0.1 released
Quick bug fix release (thanks to Peter N. for the heads up!). There was a problem with the way the runnable JAR was packaged. A new version can be downloaded from the Camshaft downloads page.
Camshaft is a Java command-line utility that executes MDX queries against a given cube and returns the results in a sensible format for loading or processing with your own tools (as opposed to you having to use voodoo or something to try and parse it into something usable). So stop parsing header bullshit off of MDX queries and start parsing complements from your users saying how awesome you are.
Drillbridge 1.4.0 Feature Preview: Custom Mappings
Drillbridge 1.4.0 is coming out later this month and it contains some really cool features. Today I am going to go over one of them. This feature is called “Custom Mappings” and while it’s ostensibly simple, it is a huge win for drill-through and cube design.
Consider the scenario where you are drilling from a member in the Time dimension. Drilling from January (Jan), February (Feb), and so on are straightforward (especially with Drillbridge’s convenience methods for mapping these to 01, 02 and such). Even drilling from upper-level members is a snap – Drillbridge gets handed the member Qtr1, for example, then opens the outline to get the three children, then applies the mappings to those and plugging it into the query (so the relevant query fragment might be WHERE Period IN ('01', '02', '03') or something.
Everything is great, right? Well, what about those YTD members you often see in ASO cubes as an alternate hierarchy? Something like this:
- YTD (~)
- YTD_Jan (~) Formula: [Jan]
- YTD_Feb (~) Formula: [Jan] + [Feb]
- YTD_Mar (~) Formula: [Jan] + [Feb] + [Mar]
- etc.
The problem with these members is that they are dynamic calcs with no children. So if you try to drill on this, then Drillbridge would literally be querying the database for a period member named “YTD_Feb”, for example.
I have sort of worked around this before in Studio by instead putting shared members under these. Under YTD_Jan you have a shared member Jan, under YTD_Feb you have shared members Jan and Feb, and so on. This works, although it’s a bit cumbersome and feels a little clunky.
Custom Mappings to the Rescue!
Custom Mappings is a new Drillbridge feature that allows you to specify a list of member names to use when drilling on certain member names. If a Custom Mapping is added to a report, Drillbridge will consult that first for child member names. If a mapping isn’t found then Drillbridge will just use the normal provider of mappings (e.g. it’ll open the cube outline and use that).
All that’s needed to create custom mappings is to put them in a file. Here’s an example:
YTD_Jan,Jan YTD_Feb,Jan YTD_Feb,Feb YTD_Mar,Jan YTD_Mar,Feb YTD_Mar,Mar YTD_Apr,Jan YTD_Apr,Feb YTD_Apr,Mar YTD_Apr,Apr YTD_May,Jan YTD_May,Feb YTD_May,Mar YTD_May,Apr YTD_May,May YTD_Jun,Jan YTD_Jun,Feb YTD_Jun,Mar YTD_Jun,Apr YTD_Jun,May YTD_Jun,Jun YTD_Jul,Jan YTD_Jul,Feb YTD_Jul,Mar YTD_Jul,Apr YTD_Jul,May YTD_Jul,Jun YTD_Jul,Jul YTD_Aug,Jan YTD_Aug,Feb YTD_Aug,Mar YTD_Aug,Apr YTD_Aug,May YTD_Aug,Jun YTD_Aug,Jul YTD_Aug,Aug YTD_Sep,Jan YTD_Sep,Feb YTD_Sep,Mar YTD_Sep,Apr YTD_Sep,May YTD_Sep,Jun YTD_Sep,Jul YTD_Sep,Aug YTD_Sep,Sep YTD_Oct,Jan YTD_Oct,Feb YTD_Oct,Mar YTD_Oct,Apr YTD_Oct,May YTD_Oct,Jun YTD_Oct,Jul YTD_Oct,Aug YTD_Oct,Sep YTD_Oct,Oct YTD_Nov,Jan YTD_Nov,Feb YTD_Nov,Mar YTD_Nov,Apr YTD_Nov,May YTD_Nov,Jun YTD_Nov,Jul YTD_Nov,Aug YTD_Nov,Sep YTD_Nov,Oct YTD_Nov,Nov YTD_Dec,Jan YTD_Dec,Feb YTD_Dec,Mar YTD_Dec,Apr YTD_Dec,May YTD_Dec,Jun YTD_Dec,Jul YTD_Dec,Aug YTD_Dec,Sep YTD_Dec,Oct YTD_Dec,Nov YTD_Dec,Dec
With this Custom Mapping in place on a report, drill-to-bottom can be provided on a cube’s Time dimension YTD members. You get all of this functionality without having to tweak the outline, add a bunch of shared members, or anything. And what’s even better – you’ll even save a whole trip to the outline. If there is some member that is problematic to resolve, for some reason, or you just wanted to override the member resolution process, you could also stick it in the custom mapping.
Just for completeness, let’s take a look at the admin screens for editing and updating Custom Mappings. Here’s an overview of all of the different Custom Mappings that have been created:

Here’s a look at editing a Custom Mapping:
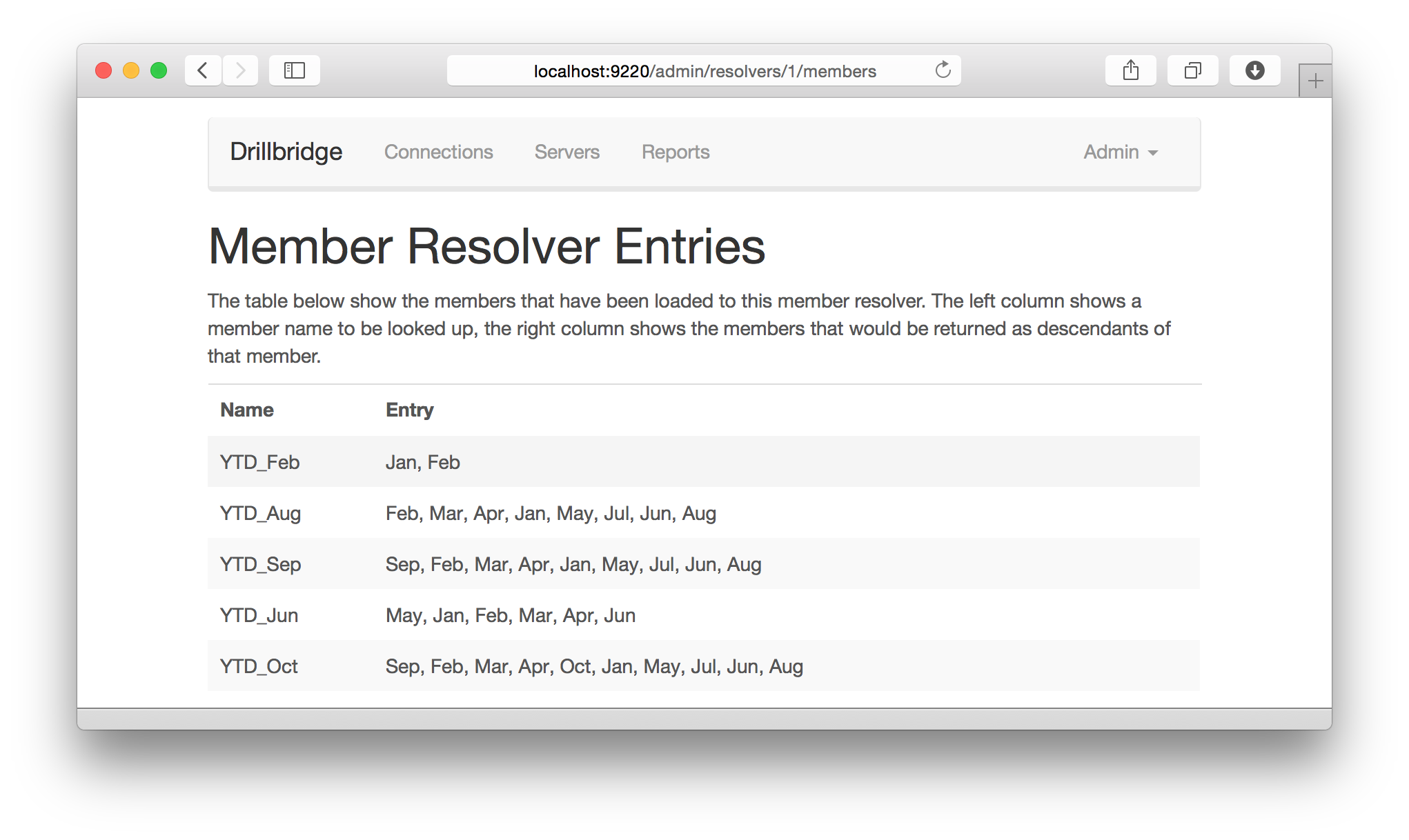
 And here’s previewing the list of individual mappings available for a given mapping (that have been uploaded by importing a text file):
And here’s previewing the list of individual mappings available for a given mapping (that have been uploaded by importing a text file):
 There you have it. As I mentioned, this feature will be available in upcoming release version 1.4.0, which should be out later this month. This feature is really, really cool, and there are a few more things this release adds that I will be talking about over the next week up to the release.
There you have it. As I mentioned, this feature will be available in upcoming release version 1.4.0, which should be out later this month. This feature is really, really cool, and there are a few more things this release adds that I will be talking about over the next week up to the release.
Drillbridge Webinar Slides Available
While not as good as the webinar with audio (are you an ODTUG member that can watch it?), here is the Drillbridge Webinar Slides for the webinar for those that are interested! Thanks again to ODTUG for all they do for the community and hosting this presentation.
Drillbridge with Teradata & Netezza?
The ODTUG webinar for Drillbridge yesterday seemed to go pretty well (more to come soon!) but one of the questions that came up is if Drillbridge works with Teradata and/or Netezza for implementing Hyperion drill-through to relational. My answer: it should, but I don’t know for sure. Drillbridge supports Microsoft SQL Server, Oracle, and MySQL out of the box. Drillbridge also allows you to put your own JDBC driver into it’s /lib folder and you should be able to use any other flavor of database that you can write SQL for: be it Informix, DB2, Teradata, Netezza, or whatever.
So that being said, if you are interested in implementing Drillbridge and using one of these backend relational databases, please don’t hesitate to reach out to me if I can help with it. I’d love to be able to confirm compatibility rather than to just say “I suspect it will work, JDBC is awesome, right?”