Welcome back to the Data Input with Dodeca blog series! We’ve already covered a good bit of ground already. To start things off, we looked at basic data input to an Essbase cube using Dodeca, then we looked at how to let users provide commentary on their Essbase data input. These are both incredibly useful features, but perhaps more importantly, form the cornerstone of many typical Dodeca applications.
Today I want to dive under the hood a bit and look at the Dodeca data audit log. Whenever data is input by a user, it’s logged. This one of the important legs of the data input stool (in addition to comments) and greatly complements data comments. Whereas data cell commentary might be thought of as being useful in a business context, the data audit log is probably more useful in an IT and SOX context. The rest of this article is going to focus on the technical details of the data audit log, while subsequent posts in this series will take a look at putting a friendlier face on it.
The Dodeca data audit log is comprised of three main tables that reside in the Dodeca repository itself. So there’s no additional setup to worry about – these tables exist out of the box.
Data Audit Log Tables
These tables are DATA_AUDIT_LOG, DATA_AUDIT_LOG_ITEMS, and DATA_AUDIT_LOG_DATAPOINTS.
DATA_AUDIT_LOG
The DATA_AUDIT_LOG table contains records of all the overall data input activities. A single data input operation may affect multiple cells of data; all of the affected cells of that are modified in a particular user action are grouped together. This table contains the audit log number (an integer primary key), the Dodeca tenant, the Essbase server/application/cube, the user, and the date the data was modified.
DATA_AUDIT_LOG_ITEMS
There are one or more audit log items associated to a single audit log. In other words, if the data audit log contains a list of transactions, then the audit log items are the list of cells (however many that my be) that were edited in that transaction. This table contains a unique ID (primary key), an association (foreign key) to the audit log table, the old value of the cell, and the new value of the cell. Note that it doesn’t not contain the members from the dimensions (that’s coming up next).
DATA_AUDIT_LOG_DATAPOINTS
The DATA_AUDIT_LOG_DATAPOINTS table contains the member names of cells that were modified. For example, consider our friend Sample/Basic. A sample intersection that was modified might be Sales, Budget, Jan, 100-10 (Cola), Washington. Each one of these would be represented as a single row in the data points table.
All Together, Now
The fully normalized format for storing modified data points tells us absolutely everything we want and need to know about data that is modified. We know the who (user), what (old value, new value), where (Dodeca app, Essbase app/cube, intersection), and when (created time). As for the why – that’s more of a commentary thing.
Given that we have all of this information, and given that it’s stored in a nice normalized form in a standard SQL database, we can query it and view/answer all manner of questions about the data. This opens up some very cool possibilities:
- Query the database directly to see what changed, if anything
- Setup an ETL process (ODI!) to provide a regular report of modified data (extra useful during the forecast cycle)
- Build a view in Dodeca itself that will allow us to query the modified data using standard Dodeca selectors (coming to a future blog post)
For now, let’s take a look at some example queries to get an idea of what we’re working with. The Dodeca repository that I’m working with the moment will be a MySQL schema. MySQL is one of the many relational database technologies that Dodeca works with. The most common ones are Oracle, Microsoft SQL Server, and DB2. But I like my Dodeca servers on a nice compact Linux server, and MySQL fits the bill quite nicely. I’ve tried to write the SQL in the most generic way possible so that if you want to borrow it for your own repository it shouldn’t need any major modifications.
To start things off, let’s say we just want a list of all of the modified data, by user, by modification time, with all data points (this could potentially bring back a lot of data in a large repository, by the way):
SELECT
AUDITLOG.SERVER,
AUDITLOG.APPLICATION,
AUDITLOG.CUBE,
AUDITLOG.USER_ID,
AUDITLOG.CREATED_DATE,
DATAPOINTS.MEMBER,
DATAPOINTS.ALIAS,
IFNULL(ITEMS.OLD_VALUE, '#Missing') AS OLD_VALUE,
ITEMS.NEW_VALUE
FROM
DATA_AUDIT_LOG_DATAPOINTS DATAPOINTS,
DATA_AUDIT_LOG_ITEMS ITEMS,
DATA_AUDIT_LOG AUDITLOG
WHERE
DATAPOINTS.AUDIT_LOG_ITEM_NUMBER = ITEMS.AUDIT_LOG_ITEM_NUMBER AND
ITEMS.AUDIT_LOG_RECORD_NUMBER = AUDITLOG.AUDIT_LOG_RECORD_NUMBER
ORDER BY
AUDITLOG.CREATED_DATE;
Note a couple of things:
- Data is sorted by date, oldest to newest
- There’s an inner join between the three tables, you must make sure that all tables are joined together
- Data that was or became
#Missingwill be null in the table. For niceness I have used anIFNULLhere to convert it to#Missing. Oracle’s equivalent isNVL. SQL Server usesCOALESCE. - This table will contain one row per dimension per modified data point (as opposed to one row per modified cell).
Okay, that’s all well and good. How about we filter things a bit and we only want to see data points that were modified in the last 30 days? Just add a simple predicate:
SELECT
AUDITLOG.SERVER,
AUDITLOG.APPLICATION,
AUDITLOG.CUBE,
AUDITLOG.USER_ID,
AUDITLOG.CREATED_DATE,
DATAPOINTS.MEMBER,
DATAPOINTS.ALIAS,
IFNULL(ITEMS.OLD_VALUE, '#Missing') AS OLD_VALUE,
ITEMS.NEW_VALUE
FROM
DATA_AUDIT_LOG_DATAPOINTS DATAPOINTS,
DATA_AUDIT_LOG_ITEMS ITEMS,
DATA_AUDIT_LOG AUDITLOG
WHERE
DATAPOINTS.AUDIT_LOG_ITEM_NUMBER = ITEMS.AUDIT_LOG_ITEM_NUMBER AND
ITEMS.AUDIT_LOG_RECORD_NUMBER = AUDITLOG.AUDIT_LOG_RECORD_NUMBER AND
AUDITLOG.CREATED_DATE BETWEEN CURDATE() - INTERVAL 30 DAY AND CURDATE()
ORDER BY
AUDITLOG.CREATED_DATE;
Please note that SQL languages differ wildly on their date math. I think the Oracle analogue here is relatively similar but SQL Server’s is a fair bit different.
Okay, how about if we’re only interested in a particular product being modified? Let’s filter on the member name/alias:
SELECT
AUDITLOG.SERVER,
AUDITLOG.APPLICATION,
AUDITLOG.CUBE,
AUDITLOG.USER_ID,
AUDITLOG.CREATED_DATE,
DATAPOINTS.MEMBER,
DATAPOINTS.ALIAS,
IFNULL(ITEMS.OLD_VALUE, '#Missing') AS OLD_VALUE,
ITEMS.NEW_VALUE
FROM
DATA_AUDIT_LOG_DATAPOINTS DATAPOINTS,
DATA_AUDIT_LOG_ITEMS ITEMS,
DATA_AUDIT_LOG AUDITLOG
WHERE
DATAPOINTS.AUDIT_LOG_ITEM_NUMBER = ITEMS.AUDIT_LOG_ITEM_NUMBER AND
ITEMS.AUDIT_LOG_RECORD_NUMBER = AUDITLOG.AUDIT_LOG_RECORD_NUMBER AND
AUDITLOG.CREATED_DATE BETWEEN CURDATE() - INTERVAL 30 DAY AND CURDATE() AND
(MEMBER IN ('Cola') OR ALIAS IN ('Cola'))
ORDER BY
AUDITLOG.CREATED_DATE;
Just to hit this home a bit, here’s a screenshot of the data that comes back for my local server, using one of my favorite SQL tools, RazorSQL:
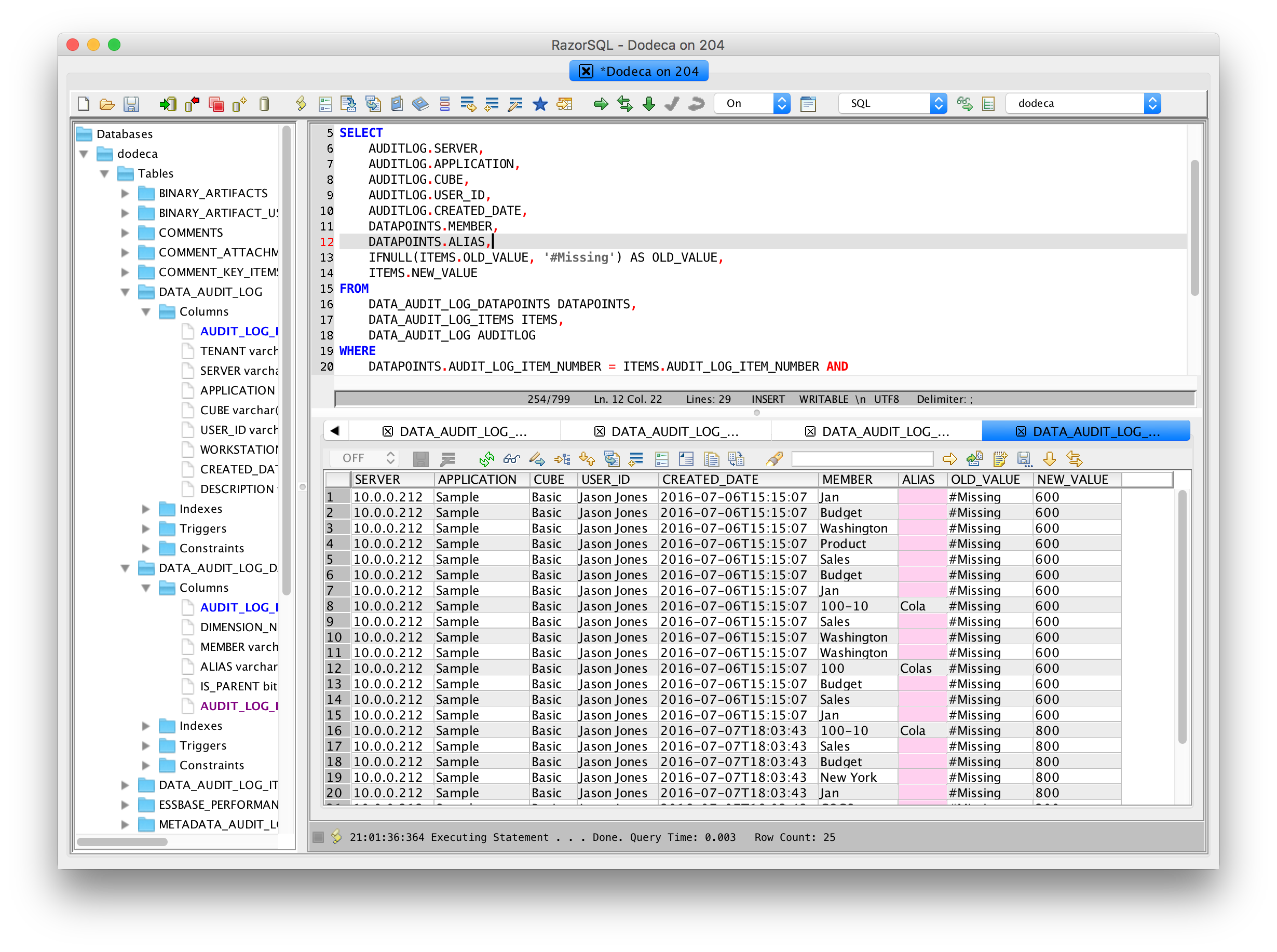
Sample query on the Dodeca repository data audit log tables
As I mentioned earlier, one of the really interesting things we can do with Dodeca is to built a view in Dodeca itself that will allow us to easily filter and see what’s going on with the data, by tapping into Dodeca’s own repository. But in the meantime I hope you found this article helpful and saw some of the possibilities that are afforded to you. Invariably when I discuss this tool with people, there is a conversational progression of yes answers that lead to data audit logging:
Does it handle data input?
Does it handle data input comments?
Is there an audit log showing me which data was modified so that I can make my IT Risk/Compliance/SOX department happy, please say yes, please say yes?
Yes!
Not sure that’d be a smart move considering Arizona is contemplating releasing Kolb and Fitzpatrick inked his deal while he was playing lights out…then faded as the season went on. In hindsight, I doubt either team is thrilled with those contracts. Might be a selling point to Alex, but probably best not to use it as leverage against the Niners.If Alex doesn’t return to the 49ers on their terms, then they can go about pursuing other options (Manning, Brees, Flynn, Johnson, etc.) while Alex tests the FA market.